For the final challenge of 2021, Luke set this challenge, to present a table containing both actual Sales values and % of Total Sales values using a single measure only.
The basic principal of this is explained within this Tableau KB article, although to get the exact display, will require a bit extra.
Building the table
Add Category & Sub-Category to Rows and Order Date to Columns. Change the Order Date so it is just displaying the month only. Add Sales to Text. Add Grand Totals and all Sub-Totals (Analysis > Totals menu). Set the totals to display at the top (Analysis > Totals menu again).
What we’re looking to do is change all the Total values in each Category section to be a % of Total instead, but just display the actual Sales value for all the other cells.
Custom Measure
IF [Size] = 1 THEN SUM(Sales) ELSE SUM(Sales)/TOTAL(SUM(Sales)) END
Add this onto the Text shelf too and edit the table calculation so both the Custom Measure and Size nested calculations are computing by the Category field only. This should give you 0s in the Total fields for the Custom Measure value.
Remove Sales from the Text shelf, as we don’t need this now.
Format the Custom Measure
Click on the Custom Measure pill and select Format. The Format dialog should present on the left hand pane.
On the pane tab, set the default format to be $ 0dp, set the Totals format to be % 0 dp and set the Grand Totals format to be $ 0dp
Change the Total Labels
Right click on one one of the Categories (eg Furniture) and Format. On the left hand pane, change the Grand Total label to be Total.
The right click and format one of the Sub-Categories and change the Totals label to be % of Total.
Colouring the cells
Add Custom Measure to Colour (ensure the table calculation is set as described above) and change the mark type to square.
Edit the colour legend to use the green-blue-white diverging palette and set to include totals and full colour range. Set the centre of the range to be 0.
This doesn’t quite give us what we need, as the % of Totals aren’t coloured as we need.
The values for these although displaying as % are essentially the values between 0 and 1. But the ‘green’ will only display for values less than 0. So we can amend the Custom Measure to deal with this
Custom Measure
IF [Size] = 1 THEN SUM(Sales) ELSE -SUM(Sales)/TOTAL(SUM(Sales)) END
We make the % of total to display as -ve, which now gives the colouring we need,
Finally, we need to ensure the -ve doesn’t display so we just need to re-custom format the Totals field of the Custom Measure to be 0%;0%
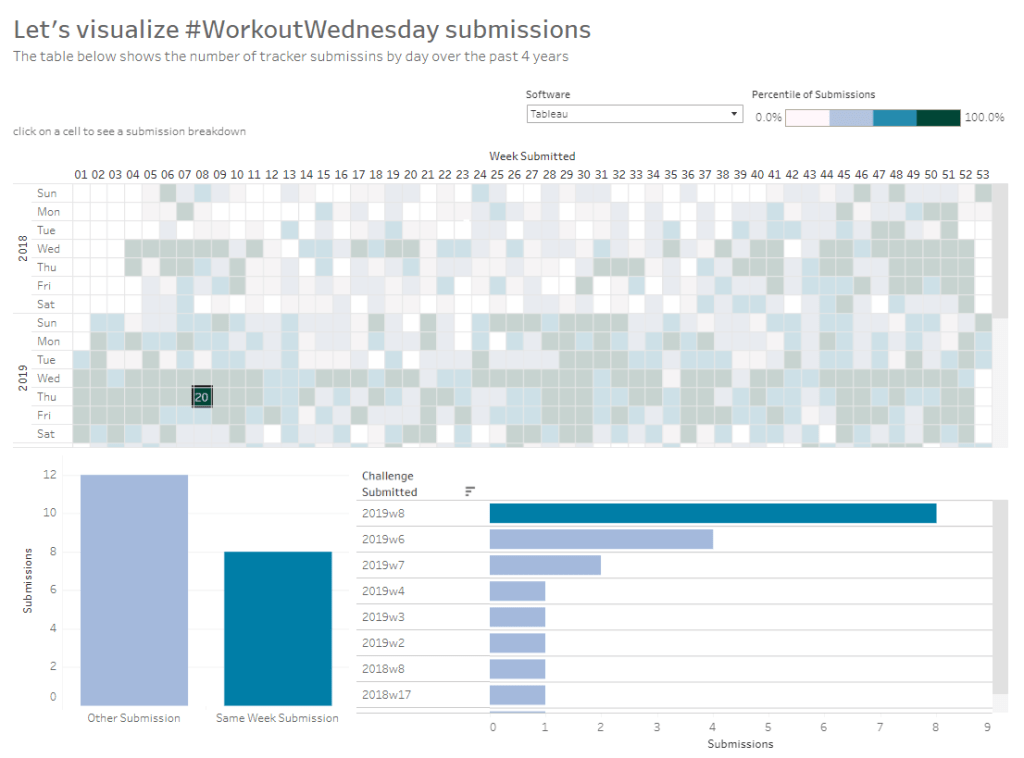
Sean Miller decided to use the data gathered by the #WorkoutWednesday team in this week’s challenge, to visualise how people use the submission tracker. I try to fill it in immediately after publishing and tweeting my solution, which is usually within the same week as when the challenge is set, unless I’m on holiday. Sometimes I do forget and as I know I’ve completed every challenge, I will fill it in if I see gaps in the tracker. However, I do think there’s something a bit awry with my submission data as there’s a few holes that don’t seem to tally properly with the weeks in the month…. there’s probably a typo or duplication in my data (if any of the team happen to read this, could you have a look.. or let me see my data to see if I can find the problem 😉 )
Anyway onto the challenge – we’re going to build a heat map and 2 bar charts and then add some interactivity between the two – nothing majorly taxing this week, so hopefully this blog won’t take too long to write… I’m prepping for Christmas so have lots to do 🙂
Building the heat map
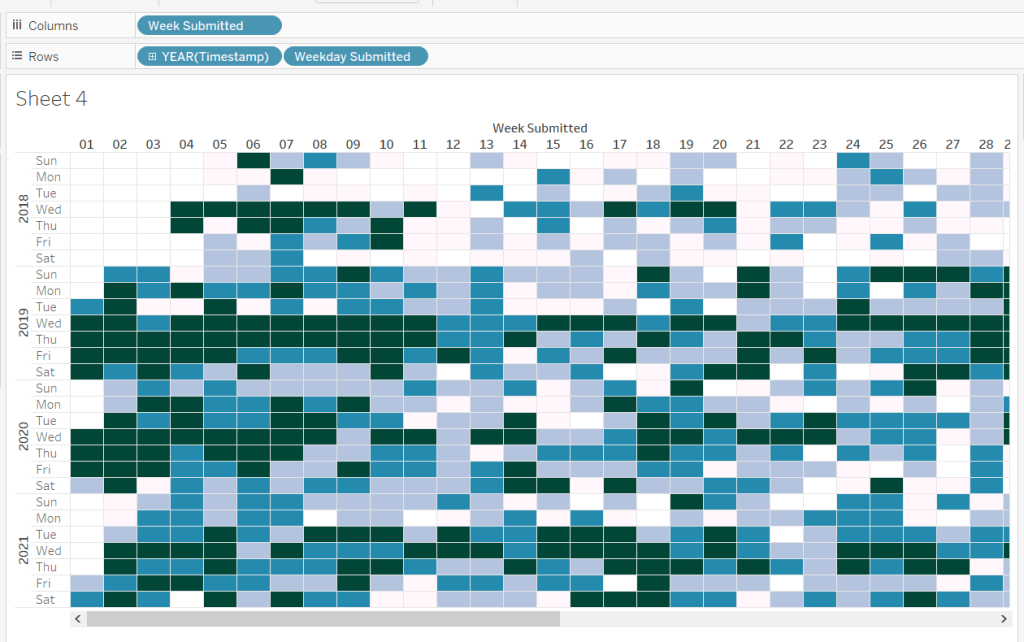
The heat map displays the week number in the year across the top, and year and day of week down the side. We need to create some calculated fields to extract some of these values from the Timestamp date field provided (note if your Timestamp field doesn’t import automatically as a date, then right click > Change Data Type > Date to convert it).
Week Submitted
DATEPART(‘week’,[Timestamp])
Format this to custom format of 00, so you display 01 rather than 1. Drag the pill into the top half of the data pane, so it’s stored as a dimension.
Weekday Submitted
LEFT(DATENAME(‘weekday’,[Timestamp]),3)
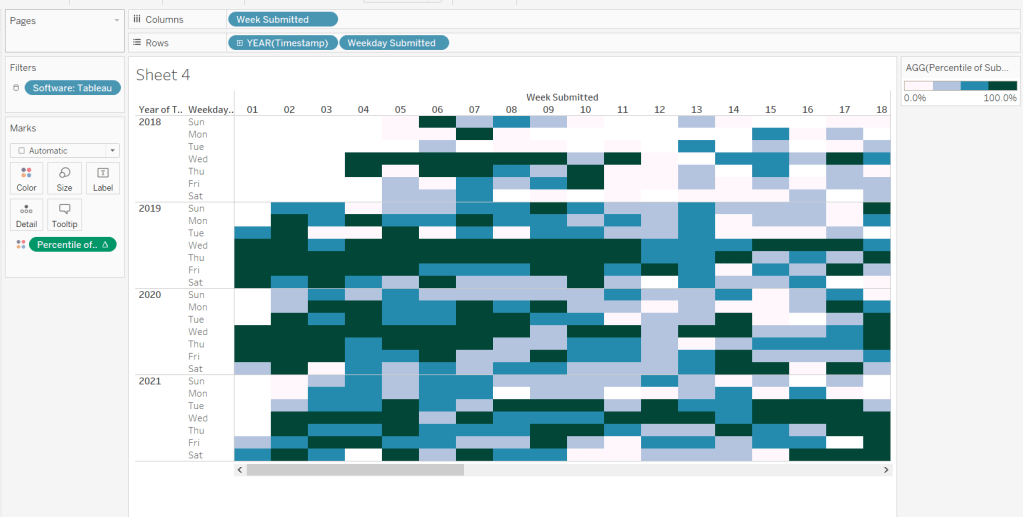
Add Week Submitted to Columns and then YEAR(Timestamp) and Weekday Submitted to Rows.
To get the numbers and display to match Sean, you will need to ensure your week starts on a Sunday. If you’re in the UK like me, you may have it set to Monday. To change this right-click on the data source > Date Properties > Week start = Sunday.
where the field referenced is automatically generated field that is created (ie what used to be Number of Records).
And then we need to calculate the Rank Percentile, which isn’t as scary as it sounds – there’s a handy function…
Percentile of Submissions
RANK_PERCENTILE([Submissions])
Format to a percentage with 1 dp.
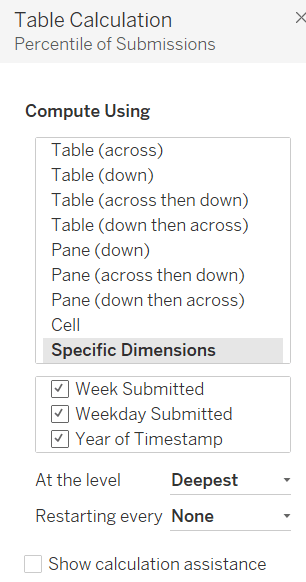
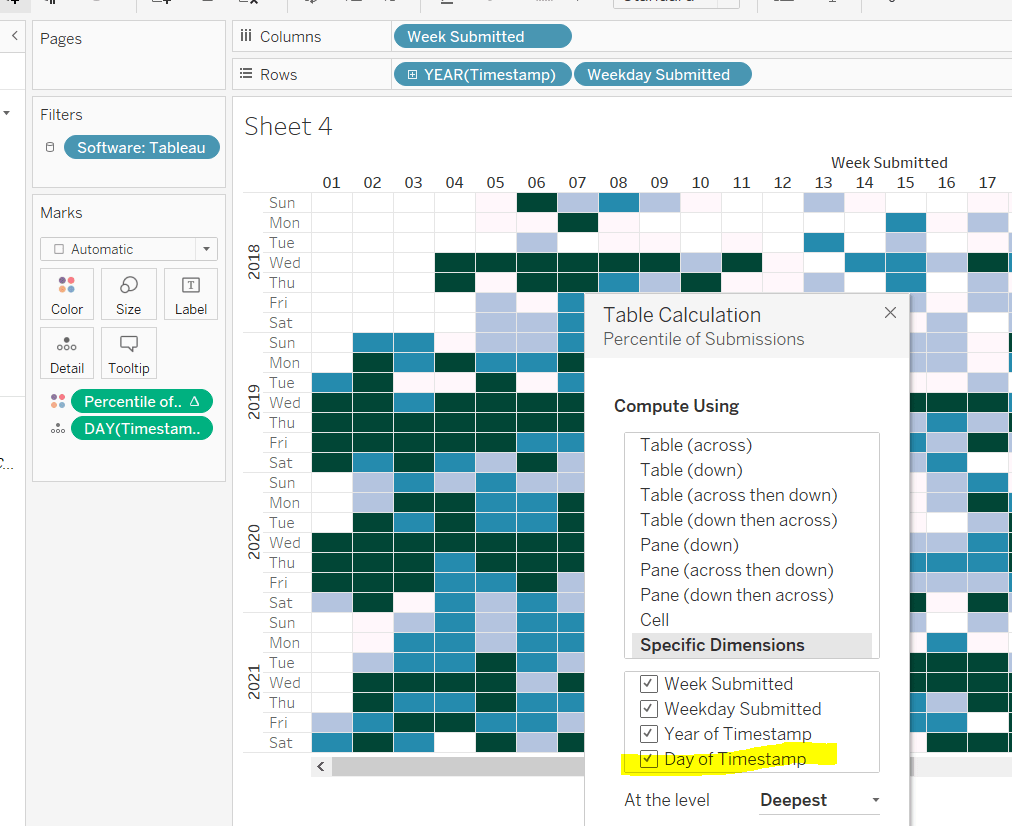
Add this onto the Colour shelf, and adjust the table calculation so it is computing by all the fields.
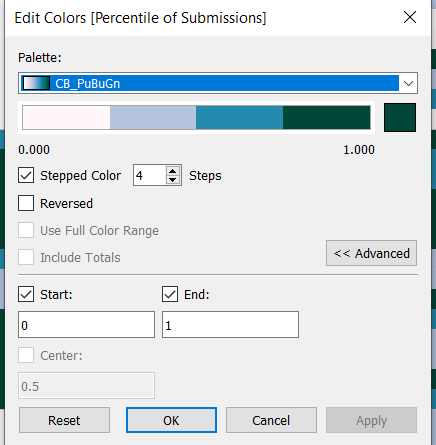
Edit the colour range to use the one specified, and adjust the settings so it only uses 4 colours, and ranges from 0 to 1
Add Software to the Filter shelf and select Tableau
This is the core of the chart complete. Add column and row dividers, rotate the Year headings, narrow the columns and hide the row label headings.
Now we just need to sort the Tooltip. Add Timestamp to the Detail shelf, and change to the Day May 8, 2015 display. This will change the viz, but don’t panic. Re-edit the table calculation so Day of Timestamp is also checked.
Then add Submissions to Tooltip and adjust the tooltip text as required.
Finally, also add Submissions to the Label shelf and edit so the value on shows on selection.
Building the bar charts
Firstly, amend the Software filter on the heatmap so it is set to apply to worksheets > all using this data source.
Next wee need to identify whether the challenge was submitted in the same wee as it was set
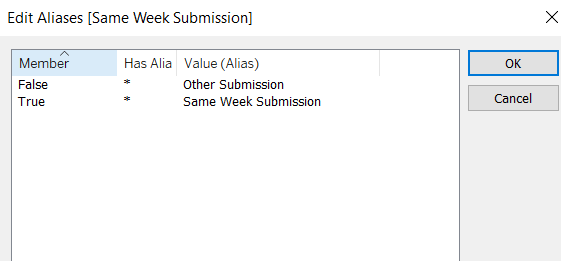
Same Week Submission
([Challenge Week]=[Week Submitted]) AND ([Challenge Year]=YEAR([Timestamp]))
This returns a boolean of true or false, but we can alias these values (right click field > Aliases) to give the displayed options
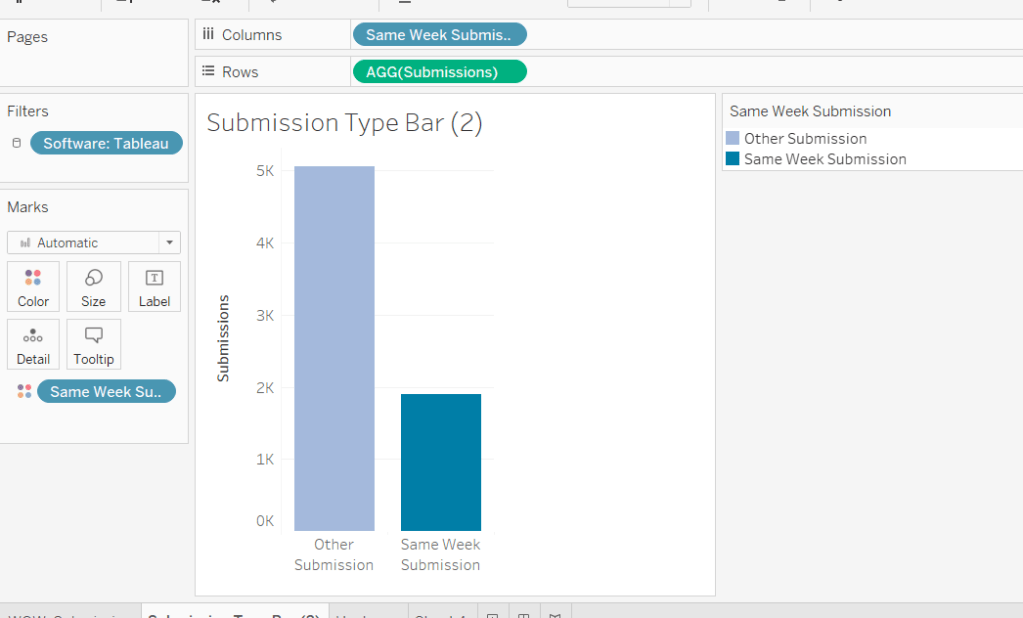
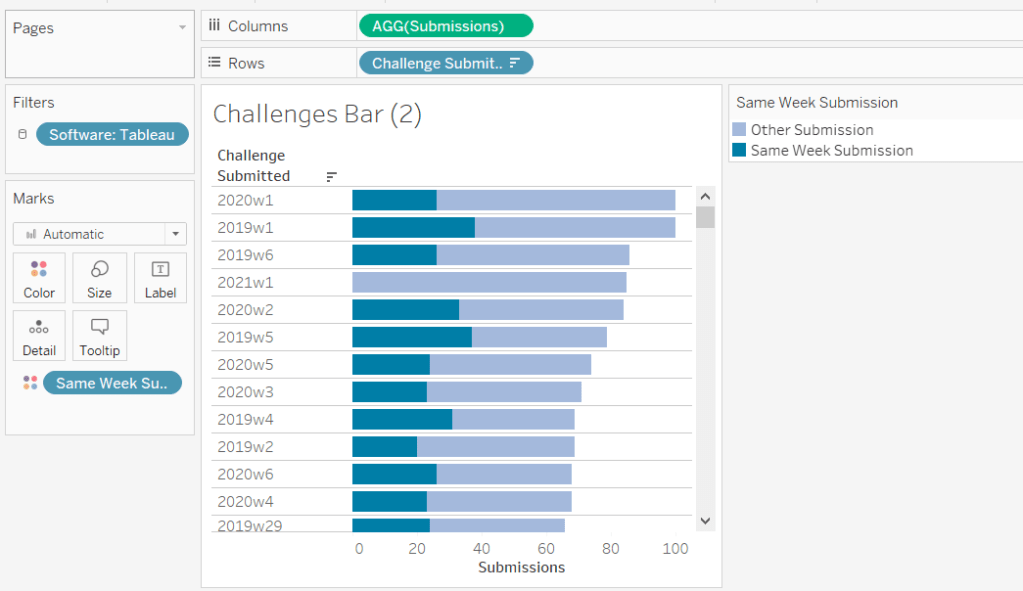
Now add Same Week Submssions to Columns, Submissions to Rows and Same week Submissions to Colour and adjust accordingly. Amend gridelines, borders etc to get the required display format
For the next bar chart we need to build the text for
Challenge Submitted
STR([Challenge Year])+’w’+STR([Challenge Week])
Add this to Rows and Submissions to Columns and add Same Week Submission to Colour. Again adjust formatting accordingly.
Adding the Interactivity
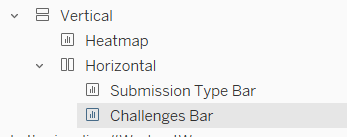
On a dashboard, add a Vertical container. Drop the Heat map into it. Then underneath, still within the Vertical container, add a Horizontal container. Add the two bar charts side by side. You may have other objects, but part of your layout hierarchy should look like
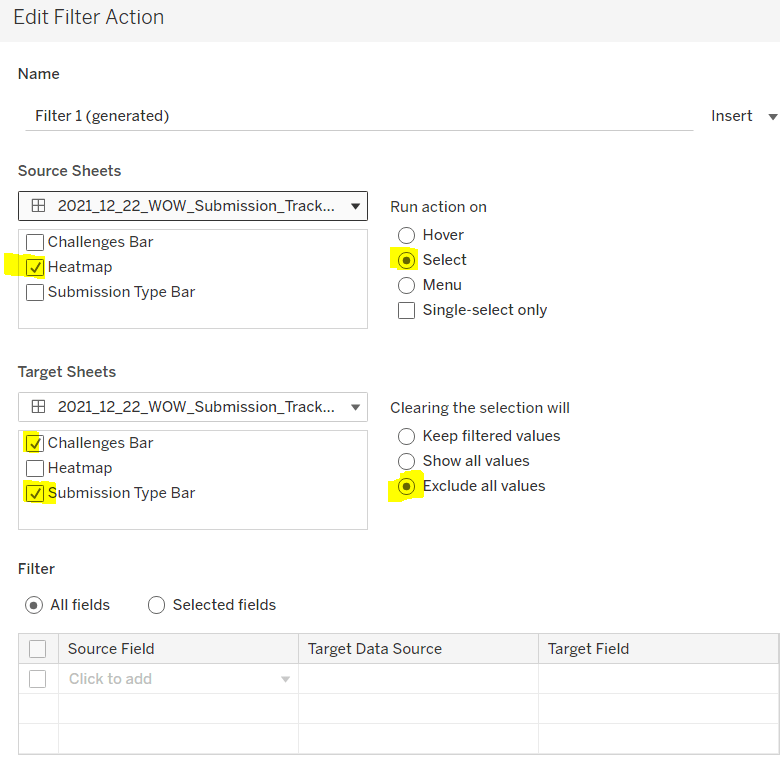
Add a dashboard filter action to the heatmap chart that on select affects the two bar charts, but when unselecting, excludes all values.
As you click on the heatmap and then unclick, the bar charts should disappear and the heat map should fill out the space.
Finalise the dashboard adding a title, supplementary text, the software filter and colour legend.
Lorna’s final #WOW challenge of 2021 was a parameter action based challenge, where the line chart at the bottom reflects the choices made by interacting with the bar chart at the top.
When I saw this was a drill down challenge, I immediately thought of previous similar challenges, so built based on the techniques I’d applied before (see this blog). This involved a parameter to capture the ‘level’ and a ‘drill down’ calculated field to pass through into the parameter on click. The solution I built (here) worked fine on Desktop (see tweet), but when published to Tableau Public, failed to display the Sub-Categories on selection :-(. I don’t know why. Having checked Lorna’s solution after, I realised I’d over complicated my solution, and had no need for the ‘level’ or ‘drill down’ fields. So I rebuilt to see if that fixed my issue with Tableau Public, and it did. So that is the solution I’ll blog about.
As stated in the requirements, I used Superstore v2021.3, but my numbers didn’t match Lorna’s. This isn’t an issue, but explains why my solution looks different from Lorna’s if you’re comparing. Having spoken to Lorna, we assume she didn’t use that version after all, but can’t recall what she may have used instead.
Anyway, onto the build.
First up, we need to define 2 parameters
pSelectedCategory
A string parameter defaulted to ‘nothing’ / empty string. This will be used to store the Category that the user clicks on in the bar chart.
pSelectedSubCat
Another string parameter defaulted to ‘nothing’. This will be used to store the Sub-Category that the clicks on in the bar chart.
We can’t just display the Sub-Category field in the bar chart, as it should only display a value ‘on click’. So we need a calculated field to store the value that needs to be displayed in the 2nd column of the bar chart – ie ‘nothing’ or the Sub-Category.
Sub Cat Display
IF [pSelectedCategory]=[Category] THEN [Sub-Category] ELSE ” END
If there’s a value in the pSelectedCategory, then display the Sub-Categorys, otherwise display a blank.
Build out the bar chart by adding Category and Sub Cat Display to Rows, and Sales to Columns. Order both Category & Sub Cat Display descending. Add Category to Colour and adjust. Label the marks, align the headings to the left, remove gridlines, hide the axis and column headings. If you show the parameter you can ‘type in’ a Category and see how the view looks.
On a new sheet, build out the line chart by adding Order Date to Columns set to the continuous (green pill) month format, and Sales on Rows. Label the max & min marks and remove all gridlines.
Create a new field which will be used to colour the line
Colour : Line
[pSelectedCategory]
Add this to the Colour shelf.
Show the pSelectedCategory parameter on the sheet and as you type in each Category value the colour legend will change. Adjust the colour for each value you type in, and for the empty value.
The line chart needs to change based on the selections made by the user, ie the values set in the parameters. A calculated field is required
FILTER
([pSelectedCategory]=”) OR ([pSelectedCategory]=[Category] AND [pSelectedSubCat]=”) OR ([pSelectedCategory]=[Category] AND [pSelectedSubCat]=[Sub-Category])
This is a boolean field. Add to the Filter shelf and set to True.
Finally, just to make things a bit more complete (and help me check the line chart was matching the selections), I created some additional fields to present on the Tooltip
TOOLTIP : Category
IF [pSelectedCategory]=” THEN ‘All’ ELSE [pSelectedCategory] END
TOOLTIP: SubCat
IF [pSelectedSubCat]=” THEN ‘All’ ELSE [pSelectedSubCat] END
I added these to the Tooltip shelf and amended the text as below
The final step is to place the two charts on a dashboard and then create 2 parameter actions, one which passes Category into the pSelectedCategory field on select. Clearing the selection needed to reset the value to ‘blank’.
The other parameter action needs to do similar, but set the pSelectedSubCat parameter from the Sub Cat Display field.
Week 49 of 2021, and it was Ann Jackson’s turn to set her final #WOW challenge (sniff sniff!). Ann’s been setting challenges for the last 4 years, and we’re all going to miss her (I’m sure she may pop up as a guest challenger at some point in the future ….).
Obviously in 4 years, Tableau has moved on, and new features make building this concept a bit more straightforward. So let’s crack on.
Modelling the data
Over the years Ann has adapted her style which includes capitalisation of text. Whilst the challenge can be built with the Tableau provided Superstore Sales data source, Ann very kindly provided her own version which already contained the capitalised fields. I used this version.
To do this type of ‘basket analysis’ you need to use 2 instances of the data source which you model using relationships as follows :
Add a relation of Order ID = Order ID and Sub-Category <> Sub-Category
This results in a data pane which lists a set of fields from the Ann Jackson Superstore data source and a set of the same fields from the Ann Jackson Superstore1 data source. In this blog, I’ll reference these data sources as AJS and AJS1. If you examine a single order with multiple sub-categories you’ll see how the data is being related
The first 2 columns above are from the AJS data source – the order contains 4 different sub-categories. The last 2 columns are from the AJS1 data source, and you can see that for each AJS.Sub-Category, only 3 AJS1.Sub-Category records are listed. This allows us to see the combination of what was ordered with what.
Building the matrix
Add AJS.Sub-Category to Rows and AJS1.Sub-Category to Columns and you have the start of your matrix.
The number of orders is displayed in each cell, which is
# Orders
COUNTD([Order ID])
Add this onto Text
This adds Null column, which is the number of orders containing a single Sub-Category.
Right-click on the word Null in the column to select the column, and Edit Alias to rename the Null to NONE.
To remove the top right hand side of the matrix, I indexed each row/column.
Sub Cat Index
INDEX()
Sub Cat 2 Index
INDEX()
Add Sub Cat Index to Rows, change to discrete (blue pill) and move to be in front of AJS.Sub-Category. Change the table calculation so that it is computing by the AJS.Sub-Category field. Each row should now be numbered from 1 to 17.
Now add Sub Cat 2Index to Columns, again change to discrete and move to be in front of the AJS1.Sub-Category pill. Edit the table calculation to verify it is computing by the AJS1.Sub-Category field. All the columns should now be numbered 1-18.
We want to remove the data for the records where the Row Index is greater then the Column Index
FILTER
[Sub Cat Index]>=[Sub Cat 2 Index]
Add this field to the Filter shelf, and set to true.
To colour the cells, add # Orders to the Colour shelf, and change the mark type to Square. Then edit the colour palette to use the Colour Brewer Blue Purple colour palette Ann advises (she’s used these palettes in the past, so I already have them installed, but you should be able to get them quickly from here).
Format the text to match mark colour and to be aligned centre. I also set the font to be Tableau Medium and bold. Set the column and row border divider lines to white.
Now uncheck show header against the two Sub Cat Index fields, and hide labels for column/ rows on the other column/row headings to remove them. Rotate the label for the columns and adjust the alignment, Adjust the font on both the column and row headers to bold and you should have the finished visual.
The Tooltips
We need to calculate the average sales contribution per order. We need 2 calculations for this, as we need to show a value for the AJS.Sub-Category on the rows and a value for the AJS1.Sub-Category displayed on the columns.
Average Sales (Rows)
SUM([Sales])/[# Orders]
Average Sales (Cols)
SUM([Sales (Ann Jackson Superstore1)])/[# Orders]
Add both of these to the Tooltip shelf. It’ll make a Null row appear – just right click and exclude.
Ann’s also been particular about some of the text displayed, so we need calculated fields to apply the required logic.
TOOLTIP – Sub Cat 2 Title
“& ” + [Sub-Category (Ann Jackson Superstore1)]
TOOLTIP- Sub Cat Text
IF [Sub Cat 2 Index]=1 THEN “SUB-CATEGORY” ELSE “SUB-CATEGORIES” END
TOOLTIP – Sub Cat 2
IF NOT(ISNULL([Sub-Category (Ann Jackson Superstore1)])) THEN [Sub-Category (Ann Jackson Superstore1)] + “:” END
Add all three fields to the Tooltip shelf, and adjust the tooltip as below
And with that, you should now have the fully completed challenge. My published version is here.
Finally, once again I want to thank Ann for all her contributions to the #WOW community over the last 4 years. I will miss her capitals and bold colour palettes – I’ll be storing away her pre-capitalised version of Superstore for sure :-)!
Candra set this seasonal fun challenge this week. It may not deliver data visualisation best practice, but as a ‘seasoned’ #WOW participant, this provided a chance to use a technique I rarely use (background images) and learn a brand new technique (colouring a bar chart with a gradient).
Getting set up
To start you’ll need to download all the files Candra provided, which will consist of the data (across 2 sheets) and 3 images.
The bauble and star image will need to be saved into your Tableau Shapes repository – I copied them into a new folder I called Xmas in this directory ..\My Tableau Repository\Shapes
The tree image just needs to be saved somewhere you’ll remember.
Building the Tree Chart
Connect to Sheet1 of the downloaded WOW Advent Calendar excel file.
Drag X to Rows and Y to Columns and disaggregate the marks (Analysis -> uncheck Aggregrate Measures)
You should get the basic layout of where the baubles are positioned. You may also notice that the X & Y values in the dataset were labelled wrong. The x-axis is your horizontal axis, but these have been stored in the Y field, while the vertical y-axis values have been stored in the X field. You may wish to rename these to save you getting confused.
Add Day to the Label shelf, and align middle centre.
We need to distinguish the bauble marks from the star mark. The star mark has a NULL value for the Day field, so we can utilise that
Day Is NULL
ISNULL([Day])
Add this onto the Shape shelf, and adjust the shape images to source the new images you saved into your shapes repository (if you can’t find them try clicking ‘reload shapes’). Adjust the initial size of the images via the slider on the Size shelf.
Now add Day Is Null to the Size shelf too. Edit the size and adjust the mark size range to suit, so the star is larger than the baubles.
Adjust the Label of the bauble so the text is larger and white.
To make the tooltip slightly more readable than that in the provided solution, I created my own custom version
Tooltip
IF [Day is Null] THEN “It’s Christmas Day!” ELSEIF [Day]=1 THEN STR([Day]) + ” day until Christmas” ELSE STR([Day]) + ” days until Christmas” END
Add this to the Tooltip shelf, and adjust so it’s just referencing this field.
Add Link to the Detail shelf – this will be needed for the interactivity later.
Now we’ll add the background image via the Maps -> Add Background Image -> <datasource> menu option. Click to add image, then browse to where you’ve saved the Xmas tree image.
We need to define the min/max coordinates for where the tree image should be positioned, and based on this, we want the horizontal X axis (the Y field) to range from 0-4 and the vertical Y axis (the X field) to range from 0 to 6. Press the Apply button and you see whether things look to be placed correctly before you close all the dialog windows.
Next we need to fix the axis, so that when interacting later, we keep the whole tree visible. The vertical axis should be fixed from 0-7, and the horizontal axis should be fixed from 0 to 4.
Then we need to remove all the axis from displaying (uncheck show header), and all row/column borders and gridlines and axis rulers.
The final step is to remove the map options from displaying when you hover over the chart – Map ->Map Options and uncheck all the options displayed in the dialog
Since the process is already documented, I don’t have to write all the steps out myself 🙂 I’ll just point out the fields I used/created, since we’re working with a different data set.
Firstly I created a new data source for this chart, which combined Sheet1 with the Range sheet, and used a relationship calculation of 1 = 1 to combine the data (Relationships didn’t exist when the blog post was written).
The equivalent of the Sales Adjusted field is the existing pre-computed Sheet1(Count) field, so we don’t need any calculated field for this.
Max Segmentsin my solution is
Max Range
WINDOW_MAX(MAX([Range (Range)]))
Note – Range (Range) is referencing the Range field from the Range table. If you just drag the field into the calculation window, it will automatically present in this way.
Total in my solution is
Total Count
TOTAL(COUNT([Sheet1]))
Sizein my solution is
Size
[Total Count]/[Max Range]
and finally Color in my solution is
Colour
([Max Range]-[Index]) * [Size]
Add Challenge Year to Rows (rather than Category), change the mark type to bar if it doesn’t change automatically. Reverse the axis so 2018 is listed at the top, then change the Challenge Year pill to be discrete (blue) rather than green.
If you follow the other blog post through, you should hopefully end up with
You then need to show the labels and adjust the tooltip against the CNT(Sheet1) marks card only.
As before, remove all gridlines borders etc.
Adding the interactivity
Add the 2 sheets to a dashboard. We need to allow the tree to filter on click of the bar chart. I used the ‘use as filter’ option on the context menu of the the bar chart object to quickly set this.
This adds a filter action to the dashboard, but is a quick way of getting it created rather than having to manually set it up via the dashboard -> actions menu.
I did use this menu though to add the URL action to the Tree sheet, which just needs to reference the Link to the Challenge field.
So a relatively short blog this week, since the most complicated section is already written up be Ken Flerlage (thanks Ken!). It was a great fun little challenge, which still allowed for plenty of learning opportunities. My published viz is here.
Sean Miller posted this week’s challenge based on the results of the annual NFL games hosted on Thanksgiving Day. It immediately reminded me of a previous #WOW challenge that Lorna posted in 2019 when she visualised Rugby League wins (see my viz here).
This is a table calculations based challenge. I did start using FIXED LoDs to help calculate the summary measures (Total Games and Win %) displayed at the front, but found that as there are 2 years (1975 and 1977) when the Dallas Cowboys did not host a game, I ended up with some pesky NULL values displaying which affected how the running sum area chart displayed.
Defining the calculations
As its a table calc challenge, I’ll build out what I can into a table to start with, to sense check I’m getting the correct numbers.
First up add Home Team, Game Date and Visiting Team to Rows and display Home Score and Visiting Score.
We start by determining the result of the fixture, based on whether it’s a home or away win or a tie. In the lollipop chart home wins are plotted at 1 and away wins at -1, so we’re going to store the result as a numeric value rather than text.
Result
FLOAT(IF [Home Score]>[Visiting Score] THEN 1 ELSEIF [Home Score]<[Visiting Score] THEN -1 ELSE 0 END)
The output is wrapped within a FLOAT, as this will help how the axis displays. Without it, by default Tableau will define the field to be a whole number, and the axis will extend to +/-2 which is too much room. We can’t adjust (fix) the axis to a decimal if the field itself is an integer, and adjusting to +/-1 chops off the displayed marks.
If you add this to the display, it will show 1, 0 -1 as you expect. You’ll notice though that the Axis on the lollipop chart is labelled as Win/Loss. This is achieved by applying a custom format to the field – “Win”;”Loss”;”Tie”
This is a sneaky but effective trick. The information stated before the first semi-colon applies to positive numbers, the info after the first semi-colon applied to negative numbers, and the information after the optional second semi-colon applies to zero.
Unfortunately though, it would appear that, at the point of writing, Tableau Public, isn’t honoring the zero formatting, and is displaying Win rather than Tie. The display works on Desktop though.
The win/loss/tie text is just a formatting feature and affects what is displayed, but the underlying value is still a number.
The Result field will be used to plot the lollipop chart. We now want a field to plot the area chart against. This is a running total of the Result values (ie win =1, win, win = 1+1, win, win, loss = 1+1 -1) and we need a table calculation.
However, as stated above due to a couple of missing years, I had to make an adjustment to ensure the running total displayed as Sean had in his challenge. I created another field
Result Adjusted
IIFNULL(SUM([Result]),0)
If the Result field doesn’t exist, as there is no data, then use 0 instead.
To see what’s going on, we’re going to need a different view of the data where the date field is continuous (green) rather than discrete (blue).
Build the below, and filter just for the first 10 years – you’ll see the gaps where the are no marks in 1975 and 1977 for Dallas
Use the context menu of the green YEAR(Game Date) pill and select the option to Show Missing Values. Marks will now display
Add Result to Label. Each mark is labelled Win or Loss, except the ones for Dallas for 1975 & 1977 as there is no data
Now add Result Adjusted to Label. A 0 value is now displayed against those two marks.
We can now build a running total off of this measure instead
Running Total Wins
RUNNING_SUM(([Result Adjusted]))
Add this to the Label too and verify the table calculation is computing by the Game Date field only. The running total for the 2 ‘missing’ dates is displaying a value which is the same as the previous value (since we’ve added 0 onto the running total). This will give us the flat line in the area chart when we come to build it.
Now back to our table of data, we can focus on the other calculated fields we need….
Total Games
WINDOW_COUNT(COUNTD([Game Date]))
This is a table calculation and is simply counting the number of distinct dates displayed. Add this to the table display we were building to start with, and adjust the table calculation to compute by all fields except Home Team. The total should display the same value for all the rows against each Home Team.
Next we want a field to indicate if the row is a win.
Is Win?
INT([Home Score]>[Visiting Score])
This is taking a boolean of true or false and converting to an INT (1 or 0).
From this we can work out the Win rate
Win %
WINDOW_SUM(SUM([Is Win?]))/[Total Games]
Add up all the Is Win? values associated to the Home Team as a proportion of the Total Games played. Format this field to a percentage with 0 dp. Again, add to the table and adjust the table calc to compute by all fields except Home Team, and verify the same settings applied to both the calculations nested in this calculation
For the All-Time Record, we need to know the number of wins and number of losses. We have a field to help us with the wins, but need an equivalent for the losses
This is the one field I kept from my LoD based attempt.
The circles on the lollipop chart are coloured based on the difference in the score, so lets’s create that
Score Difference
[Home Score]-[Visiting Score]
And finally we need some fields to help display the tooltips properly. The tooltip indicates whether the result was ‘won’ or ‘lost’ which is different text to the axis labels.
TOOLTIP-Result
IF [Result]=1 THEN ‘won’ ELSEIF [Result]=-1 THEN ‘lost’ ELSE ‘tied’ END
The tooltip also displays the scores, but the scores are always presented as highest score – lowest score and not home score – visiting score. So we need fields to store the right values
TOOLTIP–Higher Score
IF [Is Win?]=1 THEN [Home Score] ELSE [Visiting Score] END
TOOLTIP – Lower Score
IF [Is Loss?]=1 THEN [Home Score] ELSE [Visiting Score] END
Pop all these fields out onto the table, so you can validate you’ve got all your calcs right before building the viz.
Building the area chart
Add Home Team to Rows, Game Date (continuous, show missing values) to Columns and Running Total Wins to Rows (ensure table calculation set as required). Change to mark type of Area. You should have 2 horizontal lines from 1974-1975 and 1976-1977 against the Dallas Cowboys row.
Adjust the tooltip, edit the label of the Running Total Wins axis , and remove the label of the Game Date axis.
Building the lollipop chart
Now add Result to Rows directly after the Home Team pill. Change the mark type to circle.
Add Score Difference to the Colour shelf of the circle mark, and adjust the starting colour range to a dark grey. Readjust the colour of the area chart to blue too. Add a border to the area chart too (via the colour shelf).
Add another instance of Result to the Rows shelf, next to the existing one. Set the mark type of this to bar. Reduce the size to the smallest possible, set the colour to grey and remove the border.
Now set this to be dual axis, synchronise the axis, and set the marks of the 2nd Result axis displayed on the right hand side to move marks to back. Uncheck Show Header to remove this axis from displaying.
Add Visiting Team, TOOLTIP-Result, TOOLTIP-Higher Score and TOOLTIP-Lower Score to the Tooltip shelf of both the Result marks cards, and adjust the tooltip on both to
Remove the Column dividers.
Now drag Total Games to Rows and drop next to the Home Team field. Change to be discrete (blue). Verify the number is what you expect and adjust the table calc if need be.
Add All-Time Record and Win % (set to discrete) to the view too. Then format these 4 fields so the text is larger and aligned centrally.
All that’s left now is to add the sheet to a dashboard. My published viz is here.
Lorna created this challenge for #WOW2021 this week incorporating tips from the Speed Tipping session she and fellow WOW leader Ann Jackson had presented at TC21.
Defining the calculations
The requirements were to ensure there were only 7 calculated fields used, and no date hardcoding (including in the title – a feature I missed to start with). So let’s start by just going through the required calculations.
We need to identify the latest year in the data set
Current Year
YEAR({FIXED:MAX([Order Date])})
This uses an LoD (Level of Detail) calculation to identify the maximum date in the whole data set, which is 31st Dec 2021, and then extracts the Year of this ie 2021.
From this, we work out
Previous Year
[Current Year] – 1
Both of these fields return numbers, so automatically sit in the measures section of the left hand data pane (ie under the horizontal line). I want to treat these as dimensions, so I just drag the fields above the line.
We now need to create dedicated fields to store the Sales values for both years
CY Sales
IF YEAR([Order Date])=[Current Year] THEN [Sales] END
PY Sales
IF YEAR([Order Date])=[Previous Year] THEN [Sales] END
and with both of these, we can work out the
Difference
SUM([CY Sales])-SUM([PY Sales])
[TIP] This is custom formatted to △#,##0;▽#,##0.
I googled ‘UTF 8 triangles’ and used this link to find the suitable shapes which I just copied and pasted into the number format field.
We’re going to need to determine whether the difference is positive or not.
Is Loss?
MAX(0,[Difference]) =0
This is another [TIP] making use of the array function. If the Difference is negative, it will return 0 as this is the maximum of the two numbers. I’m not entirely sure if this is more efficient than simply writing Difference<=0, but I wanted to incorporate another of the tips presented.
The final calculation we need is another of the PY Sales field, as we need another distinct Measure Name value to display. I simply chose to duplicate the existing field to have a PY Sales (copy) field.
Building the viz
Add Category to Columns, Segment to Rows and then add CY Sales to Columns, which will create a horizontal bar chart. Then drag PY Sales to the CY Sales axis, and when the ‘two columns’ icon appears, drop the field.
This will automatically change the pills so Measure Values is on Columns and Measure Names is on Rows.
Swap the order of the pills on the Measure Values section on the left hand side, so PY Sales is listed before CY Sales.
Add Measure Names to the Colour shelf and adjust. Increase the width of the rows.
Check the Show Mark Labels option on the Label shelf and adjust alignment to display the text to the left
Increase the Size of the bars to the maximum size, and add a white border (via option on Colour shelf)
Add PY Sales (Copy) to Columns, and change the mark type to GanttBar. Remove Measure Names from the Colour shelf of this marks card, as it will automatically have been added. Instead add the Is Loss? field to Colour and adjust.
Add Difference to the Size shelf, then click on Size, and reduce it to as small as possible. Set the border of this mark to Automatic (it should become a little thicker).
Next add the Difference field to the Label shelf, align right and set the font colour to match mark colour.
Now make the chart dual axis, synchronise axis, and set the mark type of the Measure Names mark type back to a bar.
On the All marks card, add CY Sales, PY Sales and Difference to the Tooltip shelf. And add Current Year and Previous Year to the Detail shelf.
Adjust the Tooltip against the All marks card, so it is the same when you hover on all of the marks. And edit the title of the chart, referencing the Current Year and Previous Year fields.
The challenge has a ‘space’ between each Segment, and this is the final TIP I used.
On the Measure Values section on the left below the marks card, type in MIN(NULL). This will initially create a new ‘blank’ row between the bars and the gantt marks, which isn’t where we want the blank row to be.
To resolve this, simply click on the MIN(NULL) text in the chart and drag the text below the PY Sales (copy) text
And now you just need to uncheck Show Header against the Measure Names pill on Rows, and the Measure Values and PY Sales (copy) fields on the Columns. Then remove all row and column borders and gridlines and hide labels for rows and columns.
Hopefully you’ve got the final viz which you can now add to a dashboard. My published version is here.
Ann set this week’s #WOW2021 challenge during #TC21 and chose to live stream her build. I couldn’t watch it but I did then manage to catch a snippet of Kyle Yetter who bravely chose to share his attempt at recreating the challenge via a live stream too with Ann & Luke watching. I had already completed my build by the time I watched Kyle, and it was interesting to see where our approaches differed.
The main via is a single chart, so I started by building out all the data I needed in tabular form, so I could verify the sort.
Defining all the calculations for the main viz
First up, the data needs to be compared to ‘today’ where ‘today’ is set to 01 Jan 2022. I used a parameter to store this
pToday
Date constant set to 01 Jan 2022
We also need to understand the latest order date per customer, so need
Max Order Date By Customer
DATE({FIXED [Customer ID]: MAX([Order Date])})
and so with this we can calculate the days since last order, which is one of our key measures.
Days Since Last Order
DATEDIFF(‘day’, [Max Order Date By Customer], [pToday])
The other measures we need are
#Orders
COUNTD([Order ID])
Avg. Order Value
SUM([Sales])/[#Orders]
along with Sales and Quantity.
These are the 5 main measures displayed, but there are some additional calculations needed for the display labels and tooltips.
The label to indicate the ‘time since last purchase’ is displayed in days or years, so for this I created 2 specific fields
LABEL:Days Since Last Order
IF [Days Since Last Order] <365 THEN [Days Since Last Order] END
This will only store a value when the days is less than 365. I then formatted this field to have a ‘ days’ suffix
Similarly, I created
LABEL:Years Since Last Order
IF [Days Since Last Order]>=365 THEN [Days Since Last Order]/365 END
which stores a value for records >=365 only. This was formatted to have 1 dp and the ‘ years’ suffix instead.
The colour of the first measure is based on whether the customer is considered ‘active’ or not. The threshold for this is managed via a parameter
pActiveCustThreshold
An integer parameter defaulted to 90.
We can then create
Is Active Customer?
[Days Since Last Order]<=[pActiveCustThreshold]
This is a boolean field and will return true or false, but to get the tooltip value to display appropriately, I edited the alias of this field (right click > Aliases)
For the tooltip on the ‘total products’ (ie quantity measure), we need to display the number of distinct products orders, which we can capture in
#Products
{FIXED [Customer ID]: COUNTD([Product ID])}
Pop all these fields, along with the Customer ID and Customer Name into a table and you can see validate all the values are as you expect
Sorting the Sort
We need another parameter to manage the sort.
pSort
I used an integer parameter, but set the display to the required text strings. This is because writing logic on integers is more efficient than strings
I then created a calculated field to determine the measure to sort by
Sort By
CASE [pSort] WHEN 1 THEN SUM([Days Since Last Order]) * -1 WHEN 2 THEN [#Orders] WHEN 3 THEN SUM([Sales]) WHEN 4 THEN [Avg. Order Value] WHEN 5 THEN SUM([Quantity]) END
Notice the first measure is being multiplied by -1 since this measure is to be displayed in Ascending order rather than Descending.
In the table, amend the Customer ID pill to Sort by the Sort By field descending
Show the pSort parameter and test the functionality by switching the values.
Building the main viz
Having got all the calcs defined, this viz is relatively straight-forward. It is a multiple axis viz by Customer ID and Customer Name (note I use Customer ID as well, which I hide, just in case there are multiple customers with the same name).
Customer ID and Customer Name on Rows. Apply sort to Customer ID as described above. Hide Customer ID (uncheck Show Header). Align Customer Name to right, and adjust font.
Type in MIN(1) on Columns. Edit Axis to be fixed from 0-1. Add Is Active Customer? to Colour. and adjust. Add LABEL:Days Since Last Order and LABEL:Years Since Last Order to Label. Align Centre and match mark colour. Make sure the two fields are side by side on the label, and not underneath each other. Add Max Order DateBy Customer to the Tooltip shelf. Adjust Tooltip
Add #Orders to Columns. Strip off all the fields that have been automatically added to this marks shelf. Set the Colour accordingly. Show the Label at the end of the bar. Adjust Tooltip
Add Sales to Columns. Set the Colour accordingly. Show the Label at the end of the bar. Adjust Tooltip
Add Avg. Order Value to Columns. Set the Colour accordingly. Show the Label at the end of the bar. Adjust Tooltip
Type in MIN(0) on the Columns shelf. Change mark type to Circle. Set the Colour accordingly. Add Quantity to Label. Add #Products to Tooltip. Adjust Tooltip
Remove all row & column borders and gridlines, zero lines etc.
Add a 0 constant Reference Line to the #Orders, Sales and Avg. Order Value axes.
Hide the axes, hide field labels for rows.
Building the Viz in Tooltip
The Viz in Tooltip shows the Top 10 Products per Customer by Sales.
On a new sheet, add Customer ID, Customer Name and Product Name to Rows and Sales and Quantity (via Measure Values) to Text.
Add a Rank Quick Table Calculation to the Sales pill, then edit the table calc to be unique and to compute by Product Name
Click on the Sales rank pill , press Ctrl and drag it into the measures pane. Name the field Sales Rank. Format the field to have a # prefix. Add Sales back into the view.
Now drag the Sales Rank field from the Measure Values section and add to Rows, then change to be a discrete (blue) field, then move so it is to the left of the Product Name field. This should cause everything to re-sort into the required order automatically. It’s always worth double checking the table calc is still computing as expected.
Click on the Sales Rank pill and press Ctrl and this time drag to the Filter shelf and check values 1 to 10.
Now hide the Customer ID and Customer Name fields, and format the display.
Finally, set the display to Entire View. This will make the ‘view’ unreadable, but is necessary to ensure you don’t get a ‘viz is too large to display’ message when you get to add the Viz to the tooltip.
Adding the Viz in Tooltip
Back to the chart sheet, and edit the tooltip of the MIN(0) marks card. Insert the Top 10 sheet via Insert > Sheets. Adjust the width and height values and change the filter to just use <Customer ID>
Hovering on the circle mark should then display the Top 10 Products for that specific customer.
Adding the column headings
On the dashboard, use a horizontal layout container above the main viz. Add 6 text objects, enter the relevant text and centre. Adjust the width of each text object to line up with each column.
The help icon
Add a floating text object to the sheet – it’ll appear over the top of the chart. Position the text object to the top left, and set the background to white. Enter the text. From the context menu of the object, select the Add Show/Hide Button. Position the button in the appropriate location and resize. Edit the button options to have a grey background and show ? when hidden and X when shown.
I think that’s covered all the core points. My published viz is here.
With #TC21 looming next week, Candra’s set this week’s challenge, based on inspiration from past Tableau Conferences – a simple looking, but effective visualisation for understanding profit performance within some pre-established timeframes.
Building the BANs
Identifying Top 5 / Bottom 5 / Everything Else
Building the Chart and Labelling the Bars
Adding the interactivity
Building the BANs
The timeframes we need to report over need to be based on a specific date. In this case it’s the latest date in the data set. If you were using this for a business dashboard, you might be basing it on Today / 1st of the Current Month etc. Rather than hardcode the date I need, I’ve worked out the latest month I want to use by
Set all the Order Dates in the data set to be the 1st of the month, then get the maximum of these dates. So as the last date in the data set is 30th Dec 2021, that’s been truncated to 1st Dec 2021 which is then what this field stores.
I then want to capture the profit values for each month, quarter, year into separate fields, so we have
Month
IF DATETRUNC(‘month’, [Order Date])=[Max Month] THEN [Profit] END
This only stores Profit values for rows where the Order Date is also in December
Quarter
IF DATETRUNC(‘quarter’,[Order Date])=DATETRUNC(‘quarter’,[Max Month]) THEN [Profit] END
This only stores Profit values for rows where the Order Date is in the same quarter as December (ie the 4th quarter which is months Oct-Dec).
Year
IF DATETRUNC(‘year’,[Order Date])=DATETRUNC(‘year’,[Max Month]) THEN [Profit] END
This stores Profit data for rows where the Order Date is in the same year.
All these fields are formatted to be $ with 0 dp.
A basic viz can the be built with Measure Names on Columns and Measure Names and Measure Values on Text. The Measure Names heading is then hidden, and the font and table formatting adjusted so the sheet looks as below.
Note – Naming these fields Month, Quarter, Year rather than Monthly Sales, Quarterly Sales etc, makes this display much easier and also helps with the interaction later.
Identifying the Top 5 / Bottom 5 / Everything Else
We need to be able to identify the Sub-Categories which have the best profits, those that have the worst, and the ‘rest’. We’re going to use Sets to help us with this. However the set entries could change depending on whether we’re looking by month, by quarter or by year. So first we need to create a field that is going to store the particular Profit value we need depending on what time period is being selected.
We need a parameter pDatePart to capture the time frame. This is a string field which is just defaulted to the text ‘Month’.
The interactivity later will set this parameter to the different values.
So now we know the ‘selected’ date part, we need to get the appropriate profit value
Value To Plot
CASE [pDatePart] WHEN ‘Month’ THEN [Month] WHEN ‘Quarter’ THEN [Quarter] ELSE [Year] END
This just uses the values from the 3 measures we created to start with.
So now we can create the sets we need. Right click on Sub-Category > Create > Set and create a set called Top 5 that is based on the Top 5 Value to Plot values
Then create another set in the same way called Bottom 5
With these sets, we can now determine the Sub-Category ‘label’ that will be displayed
Sub-Category Display
IF [Top 5] OR [Bottom 5] THEN [Sub-Category] ELSE ‘Everyone Else’ END
and the grouping that will be used to colour the bars
Sub Cat Group
IF [Top 5] THEN ‘Top 5’ ELSEIF [Bottom 5] THEN ‘Bottom 5’ ELSE ‘Everything Else’ END
Building the Chart & Labelling the Bars
Ok, so now we’ve got the building blocks in place, we can build the chart. You will probably be tempted to build a bar chart (I did to start with), but positioning the labels then became a bit tricksy. When we get to the labels, we’re going to need to use the left and right alignment options. However, when you build a bar chart, if you right align the label, the label will be positioned outside at the end of the bar (even though this seems a little odd with negative values, as it looks to be on the left…).
Right aligned labels
But then we set the labels to be left aligned, the labels appear inside the bar instead, and not outside on the left.
Left aligned labels
So instead, rather than using the bar mark type, we need to build this chart using the gantt mark type, and base the Size on the Value to Plot field.
However, the value being plotted is actually an average value based on the number of Sub-Categories being ‘grouped’ as otherwise the value associated to Everything Else can end up bigger than all the rest. I created the following field
Avg Value To Plot
SUM([Value to Plot])/COUNTD([Sub-Category])
formatted to $ with 0dp.
So now we start building by adding Sub-Category Display to Rows and type in MIN(0) into Columns. Change the mark type to Gantt and add Avg Value To Plot to Size. Add Sub-Cat Group to Colour and adjust accordingly. Sort the Sub-Category Display field by Avg Value To Plot descending.
Now we can’t just label by a single field of the value or the sub-category, as while the ‘automatic’ label alignment option, almost puts the labels in the right positions, there is no way to define an ‘opposite’ to the ‘automatic’ alignment. We need to define some dedicated label fields based on where we want them to display.
Label – Left – Profit
IF [Avg Value To Plot]<0 THEN [Avg Value To Plot] END
If we’re in the bottom half of the chart, we’re going to display the Profit value on the left side.
Label – Left – Sub Cat
IF [Avg Value To Plot]>=0 THEN ATTR([Sub-Category Display]) END
If we’re in the top half of the chart, we’re going to display the Sub-Category Display on the left side.
Add both these fields to the Label shelf and then adjust the label alignment to be left.
To label the other ends, we need to create two further label fields
Label – Right – Profit
IF [Avg Value To Plot]>=0 THEN [Avg Value To Plot] END
Label – Right – Sub Cat
IF [Avg Value To Plot]<0 THEN ATTR([Sub-Category Display]) END
We then need to create another MIN(0) on Columns (easiest way is to hold down control, then click on the existing MIN(0) field and drag it next to itself to create a duplicate. Then on the 2nd marks card, remove the two Label – Left – xxx fields and add the two Label – Right -xxx fields. Change the alignment to right.
The make the chart Dual Axis and synchronise the axis.
Now you can hide the Sub-Category Display header from showing, hide the axis, remove gridlines etc.
Adding the interactivity
Once the two sheets are on the dashboard, you can add a dashboard parameter action which will on select of the KPI/BAN chart, pass the Measure Name into the pDatePart parameter. When the mark is unselected, the parameter value should stay as it is.
And hopefully, you should now have a working viz. My published version is here.
It was Sean Miller’s turn this week to set the challenge, which had an added twist – to complete only using the web authoring feature in Tableau Public, something I’d never tried before.
Most challenges use a version of Superstore Sales which I usually already have on my laptop, due to the multiple instances of Tableau Desktop installed, but this time, I had to get the data from data.world. I saved this locally then logged into Tableau Public online and started the process to build a viz online, by clicking the Create a Viz (Beta) option.
When prompted I then chose to upload from computer, the data source file I’d downloaded, and once done I was presented with the online canvas to start building
Unsure as to whether there was any auto save facility online, I decided to save the workbook pretty much immediately, although I was first prompted to navigate to the Data Sourcetab and create an Extract before I could save.
Now I was ready to start building out the requirements.
I started with the trend chart. The grain of the chart was at the month level, so I first created a specific field to store the Order Date at this particular level
Order Date Month
DATE(DATETRUNC(‘month’,[Order Date]))
I then added this to the Columns shelf as a continuous (green) exact date, and added Sales to the Rows shelf. I changed the mark type to Area, set the Colour to a blue, dropping the opacity to 50% in an attempt to match Sean’s colouring and adjusted the tooltip.
I then added another instance of Sales to the Rows shelf next to the existing one, changing the mark type of this instance to Line and setting the Colour to a darker blue at 100% opacity. I then used the context menu on this pill to set a Quick Table Calculation of type Moving Average.
By default this sets the average to the 3-month rolling average as per the requirement. I adjusted the tooltip, made the chart dual axis and synchronised the axis, then removed Measure Names from the Colour shelf that had automatically been added.
My next step at this point was to work on the filtering requirement. To help with this, the first thing I did was to Duplicate as crosstab (right click on the chart tab). This created a tabular view of the data so I could work on getting the calculations I need for the filtering. I flipped the columns and rows, so my starting point was as below.
I chose to use parameters to capture the min and max dates that the user selects on the dashboard.
pMinDate
Date parameter defaulted to 01 Jan 1900
And I also created pMaxDate exactly the same way.
I then needed fields to store the relevant dates depending on whether a selection had been made or not
Min Date Selected
IF [pMinDate]=#1900-01-01# THEN {FIXED : MIN([Order Date Month])} ELSE [pMinDate] END
The FIXED statement sets the date to the minimum month in the data set, if the parameter is set to its default. The below doed similar to get the maximum date in the data set.
Max Date Selected
IF [pMaxDate]=#1900-01-01# THEN {FIXED : MAX([Order Date Month])} ELSE [pMaxDate] END
Using these dates, I then created a field to determine whether the month was within the min & max dates
Is Month Selected?
[Order Date Month]>=[Min Date Selected] AND [Order Date Month]<= [Max Date Selected]
Pop this field onto the table view, and show the parameters and set them to some other values eg Min Date = 01 Jun 2018 and Max Date = 01 Sept 2018. You’ll also need to adjust the table calc setting of the Moving Average Sales pill to compute by Is Month Selected as well.
You’ll see True is stamped against the rows which match the date range. Now, if you make a note of the Moving Average values against these rows, and then add Is Month Selected? = True to the Filter shelf, you should get just the True rows displaying, BUT the Moving Average values are now different. This is because, with this type of field as a filter, the filter is being applied BEFORE the table calculation is being applied – the table calculation essentially has ‘no knowledge’ of the rest of the rows of data as they have been filtered out. Solving this issue is the crux of this challenge.
Remove Is Month Selected? from the filter shelf. We’re going to create a new field to filter by instead
FILTER
LOOKUP(MIN([Is Month Selected?]),0)
This field uses the LOOKUP table calculation, and is basically looking at the value of the Is Month Selected? field in it’s ‘own row’ (denoted by the 0 parameter).
Pop this onto the table view, and you can see that it’s essentially a duplicate of the Is Month Selected? field.
Now add the FILTER =True field to the Filter shelf instead, and this time the rows will once again filter as required, but the Moving Average values will be the same as those in the unfiltered list, which is what we need.
This works because the field we’re filtering by is a table calculation. When added to the filter shelf, these types of fields are applied at the ‘end’ of the processing; ie the table calculation is computed against all the rows in the data AND THEN the filter gets applied. As a result the Moving Average values are retained.
This is all part of Tableau’s Order Of Operations and is a fundamental concept when working with filters.
Armed with this knowledge, we can now apply the FILTER=True to the Filter shelf of the chart we built.
Now we can start to work on the bar charts, which will show Sales along with Average Monthly Sales. For this 2nd measure, I need to work out the number of months captured between the min & max dates.
No. Months
DATEDIFF(‘month’, [Min Date Selected],[Max Date Selected])+1
And with this I can now create
Avg Monthly Sales
SUM([Sales])/MIN([No. Months])
The bar chart viz can then be quickly created by adding Sub-Category to Rows and both Sales and Avg Monthly Sales to Columns, and sorting by Sales descending. The colours of each bar are adjusted to suit.
The bars also need to react to the dates selected, but we can simply add the Is Month Selected? = True to the Filter shelf for this, as none of the values displayed on this chart are reliant on table calculations.
To remove the gridlines from both charts, select Format > Workbook from the menu, scroll down the Format dialog displayed on the right and set Gridlines to Off
Finally, title both sheets appropriately, and then add to a dashboard. We need to add 3 actions to this dashboard – 2 parameter actions and 1 filter action.
Create a parameter action which will on Select, set the pMinDate parameter by passing the MinimumOrder Date Month, and will reset back to 01 Jan 1900 when unselected.
Then create another instance, which sets the pMaxDate parameter instead, passing the Maximum Order Date Month.
Finally, create a Filter Action which on Select of the bar chart, filters the trend chart
And with that, the challenge should be complete. My published viz is here.