This week’s challenge was a guest post by Lisa Hitch to generate a pareto chart, but adding visual clues via background colours and lines to highlight the key areas of focus.
Ultimately, this was a relatively simple table calculation challenge, requiring just 2 calculations.
Just to see what these are doing, add Customer ID into Rows and Sales onto Text. Sort by Sales descending (this is a key feature in getting the pareto chape we need).
Create another field
cust count
COUNTD([Customer ID])
and add this into the table (we ultimately don’t need this field, but just creating so it’s clear what’s happening.
Add a Running Total quick table calculation to the cust count field – the field will now show a cumulative total down the table
Also create a field
total cust
TOTAL(COUNTD([Customer ID]))
Add this to the table too – every row reports the same – the total number of distinct customers int he data set.
Now adding Running Sum % of Customers into the table, you can see that the result of this field is a calculation of cust count and total cust. We could have broken it down like this, but I chose to just use a single calculation.
We could apply similar principals to the Sales field so you can see how this is derived, but hopefully you get the gist. Ultimatel, the data we need is below
On a new sheet, add Running Sum % of Sales to Rows, Running Sum % of Customers to Columns and Customer ID to Detail. Adjust both the table calculation to be explicitly computing by Customer Id and apply a sort on the Customer ID pill, to be sorted by Sales descending.
Change the mark type to Area and adjust the colour and set opacity to 100%.
To set the background colours, we’ll used fixed reference bands.
Right click the X-axis and Add Reference Line. Select Band and then set a constant from 0 to 0.1 and colour as required.
Repeat the process 4 more times, creating bands for 01-0.2, 0.2-0.8, 0.8-0.9 and 0.9-1.
The add reference lines to provide the 20% & 80% intersection lines. This time, select the Line option and again use constants, but rather than fill, select a thick white line
Again repeat to create a line at 0.8 on the X-axis. Then add reference lines to the Y-axis at the same intervals.
Add an annotation to the point where the X-axis = 20%. Use the tooltip to find the exact point where % of customers = 20% (this can be a bit fiddly), then right click and Annotate > Mark. Edit the annotation as required, then format the resulting text box as required. Repeat for the point at which the Y-axis = 80%.
Finish off by hiding all tooltips, removing all gridlines & row/column dividers, and fixing both axes from 0-1. Then add to a dashboard and you’re done.
It’s Tableau Conference week, so this week’s challenge, set by Yoshi, was presented as part of the live session at #TC26. Yoshi set 3 levels of the challenge, to represent session data from TC25. I managed to get through the Basic and Bonus challenges
Building the Basic KPI sheet
After connecting to the data set, create a new field to determine if the session is AI related or not
AI-related
CONTAINS([Title], “AI”) OR CONTAINS([Title],”Agent”) OR CONTAINS(IFNULL([Topic],”),”Agentic Analytics”) OR CONTAINS(IFNULL([Topic],”),”Artificial Intelligence”)
Add this to the Text field on a new sheet, then adjust the text to include the rest of the words, adjusting the font style and colour as required.
Building the basic calendar sheet
Format Start Time and End Time to custom date format of hh:nn, and format Date as mmm dd
On a new sheet add Date as a discrete exact date (blue pill) to Columns and Start Time as a continuous exact date (green pill)to Rows, and edit the Start Time axis so it is reversed.
Add ID to Detail and change the mark type to circle. Create a new field
Index
INDEX()
and add this to Columns
Add AI-related to Colour and adjust accordingly. The edit the Index table calculation so it is computing by Id and AI-related only and sorted by the min value of AI-related descending, so the AI related sessions are listed first
Format the Start Time axis, so the Scale is formatted as h AM/PM and change the font style to larger, blue and bold
Format row and column dividers in the pane only to be thicker blue lines, with no dividers on the headers
Add thin blue gridlines to the Rows and remove column gridlines and zero lines
Edit the Start Time axis again, and set the Tick Marks to start at 08:00 and display every 2 hours
Remove the axis title. Hide the Index axis (right click, uncheck show header). Format the Date header fields (large, blue, bold) and remove the Date label (right click – hide field labels for columns).
Add Title, Description, Start Time and End Time to Tooltip and adjust accordingly.
Add both sheets onto a dashboard, and add an additional Text object to contain the additional explanation.
As before, add this to the Text field on a new sheet and adjust text to contain the additional wording and formatting.
Building the Bonus Calendar Sheet
Start by duplicating the basic calendar sheet. Add Session Duration to Size.
The sessions need to be sorted by the longest durations first, while still be grouped with AI -related sessions listed before non AI session. Create a new field
Sort
[Session Duration] + (INT([AI-related])*100)
I’m basically creating a numeric value to sort by, based on the duration. adding 100 if the session is AI related, ensuring the Sort value for even the shortest AI session (20 mins) will be larger than the longest non AI session (90 mins).
Adjust the Sort property on the Index field table calculation, to now sort by the minimum of Sort descending
Adjust the tooltip to include the Session Duration, and you should be done.
Duplicate your basic dashboard, then use the ‘object swap’ feature to change the 2 vizzes
For this week’s challenge, Yoshi got us creating gauge charts using Tableau’s radial viz extension.
Modelling the data
Yoshi provided a version of the Superstore dataset along with a Budget csv. After downloading, I related the 2 files within Desktop using the following relationships pictured below
Building the gauge chart
On a sheet, select the Add an extension option from the mark type dropdown and then select the Radial (by Tableau) option, and click Open on the resulting screen
Add Measure Names to Ring and Measure Values to Angle and then add Measure Names to filter and retain the Sales and Budget options only.
Click Format Extension and then set the options as follows
Total angle (degrees) : 180
Starting angle (degrees) : 270
Ring padding : 30
Segment padding : 5
Segment labels : Ring and Angle Values
Font : size 9
Centre size (%) : 50
Show centre label: on
Automatic font size: on
Edit colours and select appropriate colours
Adjust the order of the Sales and Budget pills in the Measure values pane if required
Add Region, Segment, Category and Order Date at the month-year level to the Filter shelf. Set Category to Furniture and Order Date to December 2025.
Format the Measure Values pill on the Angle shelf so that it displays the numbers as $ with 0 dp.
Create a new field
Acheivement %
(SUM([Sales])/SUM([Budget])) / 2
format this to % with 1 dp and add to the Centre shelf. Note, the division by 2 is necessary due to their being 2 measures (and therefore 2 marks) displayed and the number duplicating itself.
Create another field
Tooltip – Achievement %
(SUM([Sales])/SUM([Budget]))
Format this to % with 1 dp and add to the Tooltip shelf along with Sales, Budget and Category. Update the Tooltip to suit. Edit the title to reference the Category field, and then name this sheet Gauge – Furniture or similar.
Then duplicate the sheet. Change the Category filter to Office Supplies and name the sheet Gauge – Office. Repeat to create a version for Technology. So you should end up with 3 sheets, one for each Category. Apply the Region, Segment and Order Date filters to be shared across all 3 workbooks.
Building the bar chart
Create a field called
Sales Rank
RANK(SUM([Sales]))
and change it to be discrete (right click > convert to discrete)
Add Category to Columns and Sales Rank to Rows and Sub-Category to Detail. Set the table calculation associated to Sales Rank to be computing by Sub-Category only.
Double click into Columns and manually type MIN(1) to create a ‘fake axis’. Change the mark type to bar and edit the axis to be fixed from 0 to 1. Widen each row slightly. Then move Sub-Category to Label
Then via the Colour shelf, reduce the opacity to 0% and remove the border
Now add Sales to Columns. and on the Sales marks card, move Sub-Category back to Detail, and rest the opacity to 100%
Colour the bars as required. Add Budget to the Detail shelf, then add a reference line to the Sales axis, which shows the Budget per cell as a line with a fill below of light grey.
From one the gauge sheets, set the Region, Segment and Order Date filters to also apply to this sheet.
Add Achievement % to Tooltip and adjust the Tooltip on the Sales marks card only. Remove all the text from the Tooltip on the MIN(1) marks card.
Then format the sheet by
editing Sales axis and removing the axis title
editing the MIN(1)axis and removing the title and tickmarks
hide the sales Rank header (right click pill > uncheck show header
hide the Category header
remove row & column dividers
Then add the Gauge sheets into a horizontal container on a dashboard, setting the container to ‘distribute contents evenly’. Add the bar chart underneath, but I ‘floated’ it into position as each gauge chart object takes up more vertical space than necessary (the size of the object doesn’t adapt to the fact you’re only showing half a circle).
In this week’s challenge Yusuke wanted us to ensure filtering by date didn’t actually exclude any dimension values (so null values displayed as 0) and average calculations then accounted for those null value entries too.
Setting up the core data requirements
Yusuke provided a link to a version of Superstore which I used, since the requirements included the Manufacturer field which isn’t in the usual Excel file. I first created the hierarchy of Category > Sub-Category > Manufacturer.
Category Hierarchy
Right-click the Category field and select Hierarchy > Create Hierarchy. Name it Category Hierarchy, then drag Sub-Category and Manufacturer to be positioned under the Category field.
The display shows the number of orders, so we need
#Orders
COUNTD([Order ID])
Add Category to Rows and then expand to display Sub-Category and Manufacturer. Add #Orders to Text and add Order Date as a discrete (blue) pill at the Weekday level. This table highlights the ‘gaps’ which we need to display as 0. It also shows us how many rows of data we should always expect regardless of the date being filtered.
A standard ‘quick filter’ on date will just remove the rows that aren’t included in the filter, so we need to handle the date filtering using parameters.
Add this into the table, and we can see we still have blank entries.
Now the trick here, which I have to admit I just couldn’t resolve until I looked at Yusuke’s solution, is to create a new field
Index
INDEX()
and add this to the Detail shelf, and all the gaps in the #Orders in Date Range measure will be replaced by 0.
Adding the average
Move the #Orders from the Measure Values section onto Tooltip.
The add column totals (Analysis menu > Show All Subtotals). Then go into the menu again and select Total All Using > Average. You’ll have totals at the Manufacturer level and the Sub-Caetgory level
Right click on the Total label in the Manufacturer column, and Format. In the left hand pane, update the Label to read Avg.
Repeat the same by formatting the Total label against the Sub-Category column.
Now format the numbers displayed by right-clicking on the #Orders in Date Range field on the Text shelf and formatting. In the left hand pane, select the Pane tab and set the format of the Numbers in the Default section to standard and the format of the Numbers in the Totals section to 2dp.
Formatting the rest of the table
Add #Orders in Date Range to Colour. Change the mark type to Square. Edit the Colour palette and select a diverging palette (eg red-blue-white diverging) but set the centre to 0 and check the include totals checkbox.
Format the table, and select the shading tab. Set the Total header to pale orage, and row banding to pale grey at band size 1.
Then select the borders option and set the default options against cell, pane and header to dark grey. Then add thicker orange borders against the totals, and remove row dividers. Add grey column dividers.
Hide the Order Date column heading (right click the Order Date label and hide field labels for columns). Right click the Order Date pill in Columns and format; set the Dates option to display abbreviation
Format the font of all columns to be the same (I used Tableau Medium, black).
We want to display a * to indicate null values, so create
Number prefix *
IIF(([#Orders in Date Range])=0,’*’,NULL)
Add to the label shelf and adjust the position of the fields on that shelf.
The create
Tooltip – 0 orders
IIF([Number Prefix ]= ‘‘, ‘* No orders found for this period’, NULL)
and add to the Tooltip shelf and adjust the Tooltip to suit. Then add Category to filter and select all options.,
Collages / expand the viz and adjust the dates to test the functionality and display.
Creating the date filter & Apply button
On a new sheet, double click in to the space below the Marks shelves and the type ‘Apply’. Move the field created from Detail to Label. Change the mark type to square, adjust the size to be as large as possible and then set the fit to entire view. Format the Apply label to be centred and larger font.
Add Order Date to the Filter shelf, select range oi dates and enter values from 11 Jul 2025 to 23 Jul 2025. Show the filter, and the add the Order Date filter to context.
Create new fields
Min Date
MIN([Order Date])
and
Max Date
MAX([Order Date])
and add both to the Detail shelf.
Create a new field
Colour
[Min Date]= [pMinDate] AND [Max Date]= [pMaxDate]
And add to the Colour shelf. Adjust the colour of the true option to pale grey. Then change the value in the Order Date filter, so the colour shows as false and adjust colour to orange. Hide the tooltip.
Finally create fields
True
TRUE
and
False
FALSE
and add both to the Detail shelf.
Building the dashboard
Use layout containers with padding to add the table viz and the apply button viz to a dashboard. Show the Category filter for the table viz, and the Order Date filter for the apply button viz. Below is how I arranged my layout containers
Create the following dashboard actions:
Set Min Date
On select of the Apply Button viz, target the pMinDate parameter passing in the value from the Min Date field.
Set Max Date
On select of the Apply Button viz, target the pMaxDate parameter passing in the value from the Max Date field.
Deselect Button
On select of the Apply Button viz on the dashboard, target the Apply Button sheet directly, selecting the fields True = False.
Finally add a floating text box to provide a key for the * indicator.
string list parameter containing values week, month and quarter; defaulted to month. Note the capitalisation of the display as value. The value itself should all be lowercase as it will be referenced in calculations later.
pTimeFrame
integer parameter ranging from 12 to 36, with a step-size of 6 and defaulted to 24
pMoveAvg
integer parameter ranging from 3 to 12 with a step size of 3 and defaulted to 3
Creating the calculations
The viz needs to display a dynamic date based on thevalue of the pTimePortion parameter.
Display Date
DATE(DATETRUNC([pTimePortion],[Order Date]))
It also displays the moving average of Sales based on the pMoveAvg parameter.
Moving Avg
WINDOW_AVG(SUM([Sales]), -1*([pMoveAvg]-1), 0)
Note, as the moving average is to include the Sales value of the ‘current’ date, then we need to subtract 1 from the pMoveAvg parameter. Ie if the pMoveAcg parameter = 3, then we want to calculate the moving average over the ‘current’ mark plus the previous 2 marks, so -2 needs to be fed into the calculation.
Finally, we need to restrict the dates being displayed in the viz. For this I calculated
ie only include records where the Order Date is greater than pTimeFrame weeks/months/quarters prior to the Latest Date.
Building the viz
On a new sheet, display all the 3 parameters. The add Display Date as a continuous exact date (green pill) to columns and Sales to rows.
Add Moving Avg to rows, make dual axis and synchronise the axis. Adjust colours of the marks to suit.
Add Date to Display to the Filter shelf and set to True. Then add Sales and Moving Avg to the Tooltip of the All marks card, and adjust Tooltip accordingly.
Update the title of the sheet so it references the various parameters
Finally, tidy up by
removing row and column dividers
hiding the right hand axis (right click, uncheck show header)
editing the Display Date axis, so the title of the axis references the pTimePortion parameter (Note – I did find this gets ‘lost’ when publishing to Tableau Public, so I had to re-edit my viz after publishing to reapply this setting).
Then add to a dashboard, and use a horizontal layout container to organise the parameters across the top. My published viz is here.
For this week’s challenge, we’re using the data from a previous challenge and visualising it using Sam Parson’s ‘satellite’ chart idea – see here.
Modelling the data
Connect to the Food Self-Sufficiency csv file then add another connection to the Circle_Scaffold excel file. Relate the two together using a relationship calculation where 1 = 1 (ie relate every row in left hand data source to every row in the right hand).
Since we only care about data from FY2019, add a data source filter to set Fiscal Year = FY2019.
This saves us from having to apply that filter to each sheet we build.
Building a single spiral
On a new sheet, add Prefecture to the Filter shelf and select Akita-ken (which is near the top of the list and has a % value over 200%).
Create a parameter
pMinRadius
integer parameter defaulted to 500
To build the spiral, we need to plot a mark for every percentage point from 0 up to the Food Self-Sufficiency % value. For this we will need to determine an (x,y) coordinate value for each point, which will require some trigonometry, based on the diagram below
For each point on the circle, we will need to identify the x & y position of where the radius intersects the edge of the circle. As we are building a spiral, the radius of the circle will increase as we move around each percentage point, so we need
Radius
[pMinRadius]+[Path Percent Point]
We then need to determine the angle θ. As a circle is 360°, and a complete circle represents 100%, then 1% is 360/100, so the angle (in radians) for each % point plotted round the circle can be calculated as
Angle
RADIANS([Path Percent Point] * (360/100))
X
(SIN([Angle]) * [Radius])/360
Y
(COS([Angle]) * [Radius])/360
Now create the point
Spiral Point
MAKEPOINT([X],[Y])
Note– the X & Y values are divided by 360 due to the spiral we’re building and the increasing radius when displayed using map layers. If we were just plotting X against Y and not using map layers, this wouldn’t be required.
Double click on Spiral Point to automatically add Longitude and Latitude fields to the sheet.
Change the mark type to line and then add Path Percent Point to the Path shelf.
Add Prefecture to the Detail shelf, as it’ll be needed later when we build the trellis and remove the filter.
At this point, the spiral is showing 3 complete revolutions, as the data in the circle_scaffold data set contains info for up to 300%. We need to restrict it so we only show up to the Self-sufficiency ratio… so we need
Filter Percent PointDisplayed
[Path Percent Point] <=[Self-sufficiency ratio for food in calorie base 【%】]
Add this to Filter shelf and set to True.
We now want to colour the spiral based on the percentage point associated to each mark plotted being <100%, between 100% & 199% or >= 200%, so we can use
Colour – Spiral
FLOOR([Path Percent Point]/100)
which will return an integer of 0, 1, or 2
Change this field to be discrete and then add it to the colour shelf and adjust colours accordingly.
Now obviously, you might be thinking things aren’t quite right – we’re not starting at the top and rotating differently. Simply pressing the swap rows and columns icon in the menu bar will resolve this, but if we do that too early, we lose the ability to add map layers, so leave as is for now.
Add the label map layer
Create a 0 point
Zero
MAKEPOINT(0,0)
Drag this onto the canvas and drop when the Add a Marks Layer option appears
This has the effect of creating a 2nd marks card
and now we have this, we can press the swap rows and columns icon in the menu bar to get the start of the spiral at X=0
Change the mark type to circle and add Self-sufficiency ratio… and Prefecture to the Label shelf. Adjust the font style and align centrally. Set the colour of the circle to white and increase the size. Move the Zero marks card to be below the Spiral Point marks card.
Rename the marks cards if you wish.
Add the starting point map layer
We need to create a point for the start of each line which is at the 0% mark
Start Point
MAKEPOINT((IF [Path Percent Point] = 0 THEN [X] END), (IF [Path Percent Point] = 0 THEN [Y] END))
Add this as a new marks layer. Change the mark type to circle and increase the size a bit. Colour the mark to the same base colour you used for your <100% range and remove the border. Rename the marks card to 3.Start Point
Add the end point map layers
Create a new point to represent the end of each line
End Point
MAKEPOINT((IF [Path Percent Point]= [Self-sufficiency ratio for food in calorie base 【%】] THEN [X] END), (IF [Path Percent Point]= [Self-sufficiency ratio for food in calorie base 【%】] THEN [Y] END))
Add this as a new marks layer. Change the mark type to circle and increase the size a bit. Add Colour-Spiral to the Colour shelf as a discrete dimension (blue disaggregated pill) and remove the border. Rename the marks card to 4.End Point Outer.
Add another instance of End Point as another marks layer. Again change the mark type to circle and adjust the size so it is smaller than the previous circle, and set the Colour to white. Rename the marks card to 5.End Point Inner.
Tidy up by
removing the Tooltip from each layer
disabling selection of each map layer (so nothing happens when you hover over it)
Hide the axis
Remove axis rulers and gridlines, but make sure the zero lines are shown
Hide the null indicator
Name the sheet Single Spiral or similar.
Building the trellis
Duplicate the single spiral (so if things go awry, you can get back to this). Then start by adding Prefecture to the Detail sheet of all the marks card.
When creating trellis charts, we need to create fields that represent which row and which column each Prefecture should sit in. There’s lots of blogs on creating trellis charts. As we know the number of rows and columns we need, I created
Cols
INT((INDEX()-1)%10)
Rows
INT((INDEX()-1)/10)
and make both fields discrete.
Add Cols to Columns and Rows to Rows. Adjust the table calculation setting of each field so it is computing by Prefecture only, and custom sorted descending by Self-sufficiency ratio…
Then show the Prefecture filter and select all values to display the ordered set of Prefectures.
Hide the Rows and Cols fields, remove row & column dividers. Adjust the size of the start and end point circles to suit, and if the zero lines aren’t showing, reduce the size of the label circle map layer and fit to Entire View.
Then name this sheet Trellis or similar and add to the dashboard.
After connecting to the data, add Team to Rows and Timestamp as a continuous (green) pill at the Day level to Columns. Create a new field
Call Count
COUNT([synthetic_call_center_data.csv])
and then add this to Rows.
Add Timestamp to Filter, and select relative date. Set the options to Last 3 weeks, and then additionally check the anchor relative to check box and enter 23 Dec 2024. This is because the data set only goes up to the end of December 2024. Not setting this field will apply the date filter based on ‘today’ so it’s unlikely anything will appear.
(Note – you may also need to update the date properties of the data set to ensure a week starts on a Sunday to get matching numbers: right click the data source and select the date properties option).
To add a marker to the last point, create a field
Call Count – Most Recent
IF LAST()=0 THEN [Call Count] END
Add this to Rows and adjust the table calc setting so it is computing specifically by Day of Timestamp only. By default it was doing this via the Table (across) option, but I tend to always prefer to always explicitly fix what the calculation is computing over, as it won’t then matter where I then move that field too if I choose to change the layout of the viz.
Set the mark type on the Call Count marks card to line, and then adjust the colour to grey and reduce the size. Set the mark type of the Call Count – Most Recent marks card to circle, set the colour to blue and increase the size. Hide the null indicator (right click > hide).
Set the chart to dual axis, synchronise the axis and then remove the Measure Names field from the All marks card.
remove both the axis titles (right click axis > edit axis), hide the right hand axis (right click, untick show header), and format to remove the column divider from the header section only.
Now we’ve got the core display, we need to create the following fields
No. of Calls
WINDOW_SUM([Call Count])
Highest Call Vol
WINDOW_MAX([Call Count])
Lowest Call Vol
WINDOW_MIN([Call Count])
Avg Call Vol
WINDOW_AVG([Call Count])
format this to a number with 0 dp
Calls this period
WINDOW_MAX([Call Count – Most Recent])
the window_max is required here, as the data set we’re displaying at the day level, has 2 values – the latest value and null. We only want to return 1 value, which is the maximum of these.
Previous Period
WINDOW_MAX(IF LAST()=1 THEN [Call Count] END)
LAST()=1 returns the value of the next to last record, and the window_max is again applied, as the nested IF clause will return null for all others records.
Period Var
[Calls this period] – [Previous Period]
Add each of these fields, one by one, to Rows following the steps below
Add to rows (it will automatically display as a green continuous pill).
change to discrete (right click on the pill and select discrete – the pill will turn blue and move to before the green pills)
Explicitly set the table calc to be computing by Timestamp (as above)
Once, you should have something that looks like this
but I noticed, that the display in the solution is sorted based on the total number of calls and not by Team, so add a Sort to the Team pill to sort by Call Count descending
Update the Tooltip if you wish, and then add the viz to a dashboard, floating the Timestamp filter.
For this week’s challenge, Lorna visualised the output of a crazy golf game she had with the latest Data School cohort, and thought it would be a fun challenge to share.
While the data set is very small, there’s several core calculations required, which we’ll start off creating.
Defining the core calculations
After connecting to the data, I initially dragged the Hole field from Measures to Dimensions (dragged it to be above the line on the data pane).
We need to know the average score per person (across all 11 holes)
Overall Average Score
{FIXED [Person]: AVG([Score])}
format this to 1dp
We also need the average score per hole
Avg Score Per Hole
{FIXED [Hole]: AVG([Score])}
format this to 1 dp
We need each person’s score up to 9 holes
Score up to 9
{FIXED [Person]:SUM( IF [Hole]<=9 THEN [Score] END)}
We need the tie break score for the 10th & 11th holes
Tie Break
{FIXED [Person]:SUM( IF [Hole]>9 THEN [Score] ELSE 0 END)}
We need the average score across 9 holes
Avg Score
[Score up to 9]/9
format to 1 dp
We need to the lowest score per person
Lowest
{FIXED [Person]: MIN([Score])}
With this information, we can then define a field we can use for sorting which is a numeric field that is a combination of multiple fields as stated in the requirements
Sort
(SUM([Score up to 9])*10000) + (SUM([Tie Break]) * 1000) + (SUM([Avg Score]) * 100)+ SUM([Lowest])
Building the Heat Map
On a new sheet add Score up to 9 to Rows and change it to be discrete. Repeat the same for Tie Break, Avg Score and Lowest. Then add Person to Rows and Hole to Columns.
Double click into Columns and manually type MIN(1.0) to create a ‘fake axis’. Change the mark type to bar and increase the Size to the maximum. Edit the axis to be fixed from 0 to 1 and the hide the axis. Manually increase the width of each row and set the chart to fit width.
Add Score to Colour and choose a diverging colour palette and then manually change the start & end colours to match the solution (or define your own colour style). I used #62a14b (green) and #13316d (dark blue). Check the box to use full colour range
Update the Tooltip as required.
We then need to include some indicators on the heat map. To determine the arrow indicator we first need
Previous Score
LOOKUP(SUM([Score]),-1)
and then create
Change Indicator
IF SUM([Score]) > [Previous Score] THEN ‘↗’ ELSEIF SUM([Score]) < [Previous Score] THEN ‘↘’ ELSEIF SUM([Score]) = [Previous Score] THEN ‘→’ END
Add these to Label too and adjust label so it is aligned bottom centre, and coloured white. You may need to adjust size of font for each label item, and increase the height of each row to get the information to display.
Finalise the formatting by
Set the background colour of the whole sheet to #7299aa
Set the font of all the column headings and label headings to Tableau Medium, 9pt, white
Hide the Hole label heading (right click the label and hide field labels for columns)
Add a white border to the bars via the Colour shelf
Remove all column dividers
Remove row dividers from the pane only, ensure the row dividers for the headers remain.
Remove all gridlines , zero lines, axis rulers & ticks
Name the sheet HeatMap or similar.
Building the Average Score Per Person bar chart
On a new sheet, add Person to Rows and Overall Avg Score to Columns. Add a Sort to the Person pill that references the Sort field ascending
Add Overall Avg Score to the Colour shelf, and then adjust the colour scale so it uses a diverging colour scale which is then edited to use the same colour range as before and spans the same range, which means explicitly stating the start (-1) , middle (0) and end (10) values
We want to display a * against the winner
Winner Icon
IF SUM([Overall Avg Score]) = WINDOW_MIN(SUM([Overall Avg Score])) THEN ‘★’ ELSE ” END
Add this to Rows and adjust the table calculation so it is explicitly computing by Person only.
Create
Winner Label
IF SUM([Overall Avg Score]) = WINDOW_MIN(SUM([Overall Avg Score])) THEN ‘Coach Always Wins!’ END
and add this to Label along with Overall Avg Score. Increase the width of the bars to see the text and align middle left and change the font to white. Adjust the Tooltip.
Format the sheet
Set the worksheet background colour
Hide the Person column (uncheck Show Header)
Hide the Overall Avg Score axis (uncheck Show Header)
Remove all column/row dividers, gridlines, axis lines, zero lines
Add a white border around the bars (via the Colour shelf)
Increase the Size of the bars so there is a small gap between
Format the * to be white font
Hide the Winner Icon label (right click > hide field labels for rows)
Make the Winner Icon column as narrow as possible
Name the Sheet Avg Per Person or similar.
Building the Average Score Per Hole bar chart
On a new sheet, add Hole to Columns and Avg Score Per Hole to Rows. Add Avg Score Per Hole to Colour and adjust the scale as we did above so it ranges from green to blue and -1 to 10.
Show mark labels, adjust the tooltip. Set the background colour of the worksheet and remove all gridlines, zero lines, row/column dividers etc. Hide the Avg Score Per Hole axis and the hole labels (uncheck show header on the Hole pill). Adjust the font of the labels to be Tableau Medium and white. Add a white border around the bars. Increase the Size to leave a small gap.
Name the sheet Avg Per Hole or similar.
Building the dashboard
Set the background of the dashboard to the same colour of the worksheets.
Using containers, add a horizontal container and add a text object (for the title), the Avg Per Hole sheet and then a blank object. Remove the container that gets added with the colour legend.
Add another Horiztonal container beneath and add the Heatmap sheet and the Avg Per Person sheet.
Remove all padding. Remove all titles from the sheets. Set all the charts to fit entire view. Manually line up everything, but you’ll find you have an issue getting your horizontal bar chart to align to the player rows due to the header in the heatmap
(Note – you may notice your labels on the heat map aren’t displaying due to the space available). You can continue to adjust on Desktop so they do appear (make the heatmap have more vertical space), or wait until you’ve published to Tableau Public and see if you get the desired result… although at the point of writing , Tableau Public is having issues with the table calcs and causing odd behaviour with the display).
To fix this, go back to the Avg Per Person sheet and double click into column and manually type “” to create a dummy header row with no text. Hide the “” label (right click > hide field labels for columns). You can then adjust the height of this header label section to help get the alignment right.
Then make any final adjustments required – add the title, and any imagery etc. My published viz is here.
For this week’s challenge we’re going to look at building an alternative to a stacked bar chart. This challenge was inspired by this post by the Flerlage twins, which in turn was inspired by other members of the #datafam community. Once again, we’re making use of some Premier League data.
Building the viz
Add Team to filter and select Manchester United, Chelsea, Arsenal and Manchester City then add Season to filter and select the last five seasons. Then add Team and Season to Columns and Points to Rows.
Sort team by the field Points descending. Add Team to colour and adjust accordingly. Show Mark labels to display the number of points for each bar.
Add subtotals via the analysis menu > totals > show all subtotals
Hide the subtotal bar by clicking on one of the total bars and selecting hide from the drop down which is defaulted to automatic
Right click on the Total label on the axes and select format – in the left hand side, delete the label field
Create a new calculated field
Total Points
WINDOW_SUM(SUM([Points]))
And add this to rows. Remove Team from the colour shelf on the marks card, and change the colour to pale grey. Increase the size of the bars to be as wide as possible. Uncheck show mark labels. Hide the total bar like we did above.
Make the chart dual axis and synchronise axis. If need be, right click the right axis and move marks to back. Adjust the table calculation on Total Points so it is computing by Season only. Hide the total bar again if it reappears.
We want to label the total bar with the Team and the Total Points so we need to create some more calculated fields
Label: Team
IF [Season] = ‘2021-22’ THEN [Team] ELSE NULL END
We’re being sneaky here, and just labelling the central bar.
Label: Total Points
IF MIN([Season]) = ‘2021-22’ THEN [Total Points] END
Add Label: Team to the label shelf of the Total Points marks card and adjust so it is an attribute – this means it’s not referenced in any table calculations. Add Label: Total Points to the label shelf too.
Adjust the label as required and then change the alignment so the direction of the text is swapped. Format the font as desired.
Delete all the text from the Tooltip on the Total Points marks card and adjust the text on the Points marks card to match the required format.
Hide the right hand axes (right click axis > uncheck show header). Hide the Team column heading. Remove all gridlines/ axis lines/ zero lines and row and column dividers.
Hide the Season label heading (right click on the label > hide field labels for columns).
Format the axes font to be smaller and rotate the axes labels on the Season axis.
Name the sheet Bar chart or similar and add to dashboard.
Erica set this week’s challenge, focusing on the ability to compare specific entities against themselves and ‘the whole’ without resulting in a mess of coloured spaghetti. 3 levels of difficulty were provided. As it stated the levels didn’t necessarily follow on from each, I just built (and am therefore blogging about) level 3 – the advanced challenge.
Defining the core parameters
For the user to select the main element they want to analyse we need
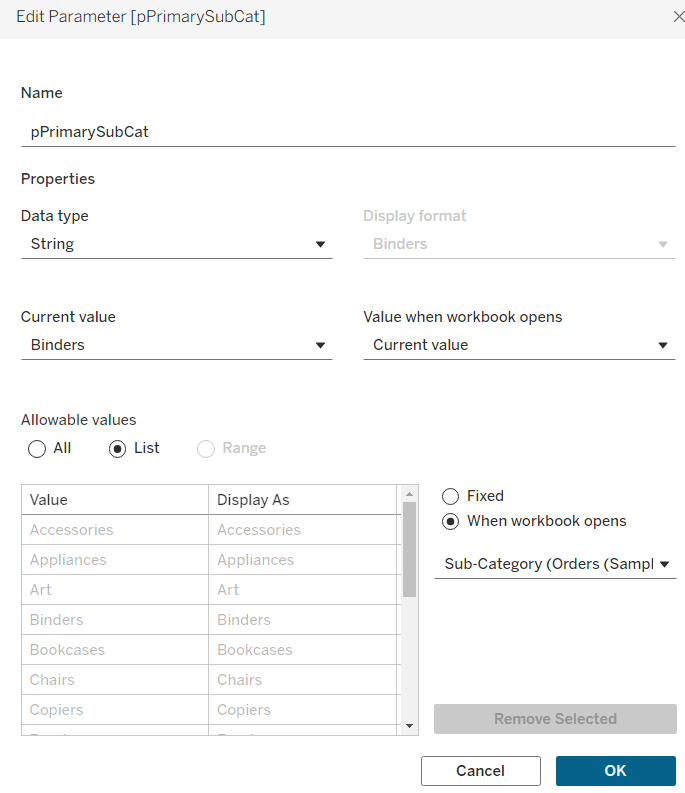
pPrimarySubCat
string parameter, that is sourced from a List based on the Sub-Category field when the workbook opens. Default to Binders.
This parameter will be visible to the user to select from a drop down list control.
To capture the secondary element to compare against, we need
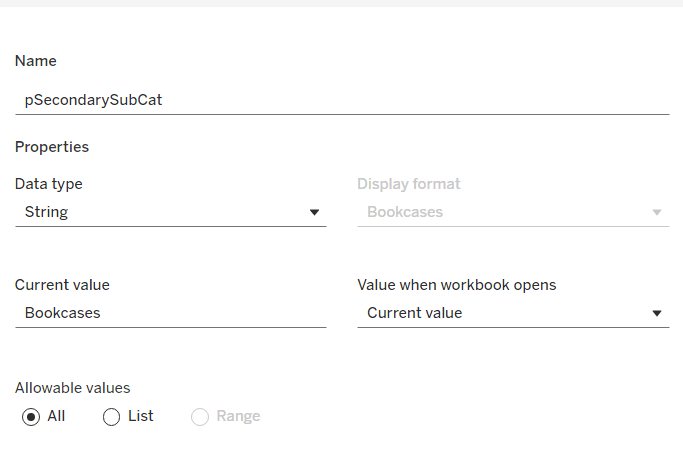
pSecondarySubCat
string parameter defaulted to Bookcases.
This is just a ‘type in’ field, that won’t ultimately be displayed to the user, but populated via a dashboard parameter action on select of a line in the chart.
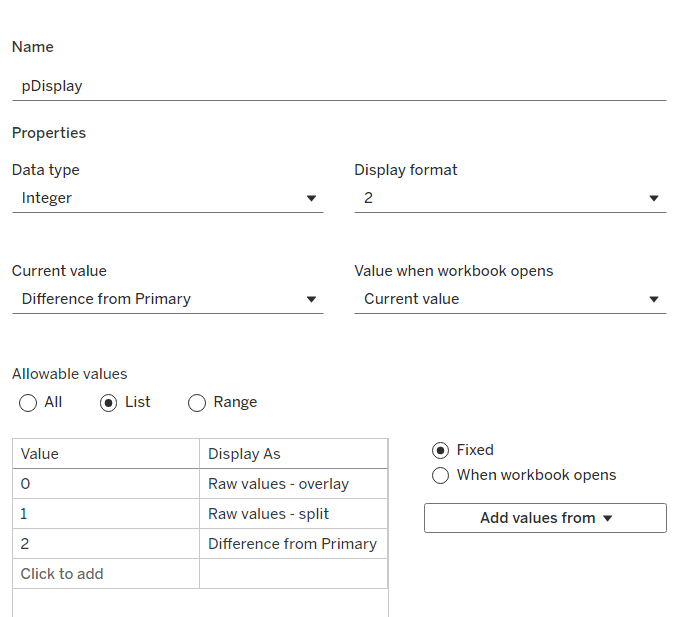
To control the different type of display options, we need
pDisplay
integer parameter sourced from a manual list which aliases the integer values for the displayed text strings. Defaulted to 2 (Difference from Primary)
Defining the additional calculations
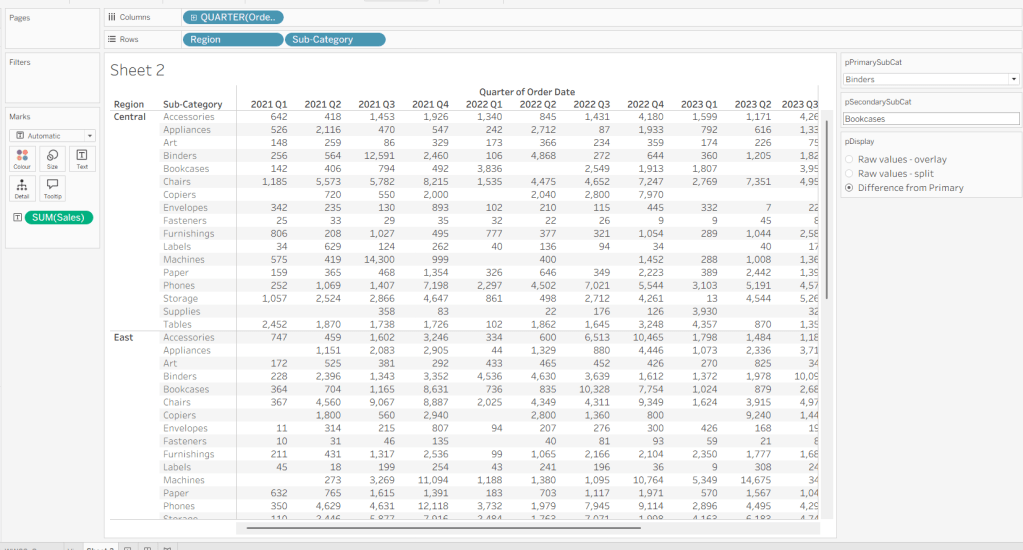
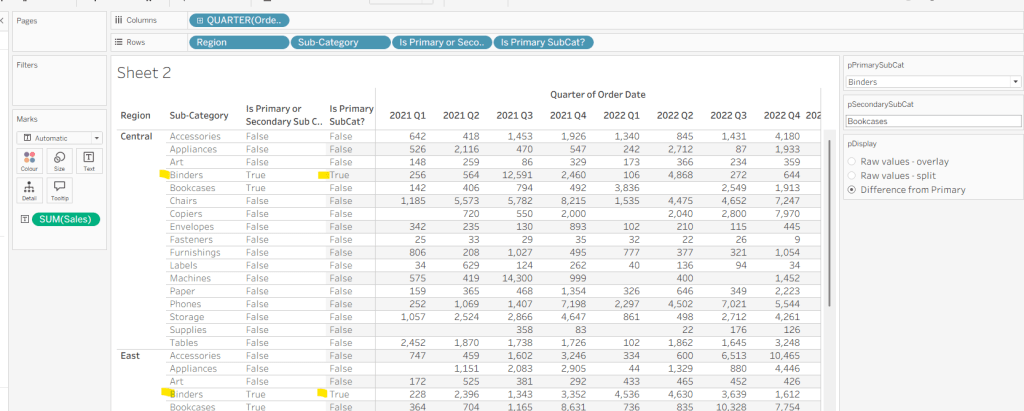
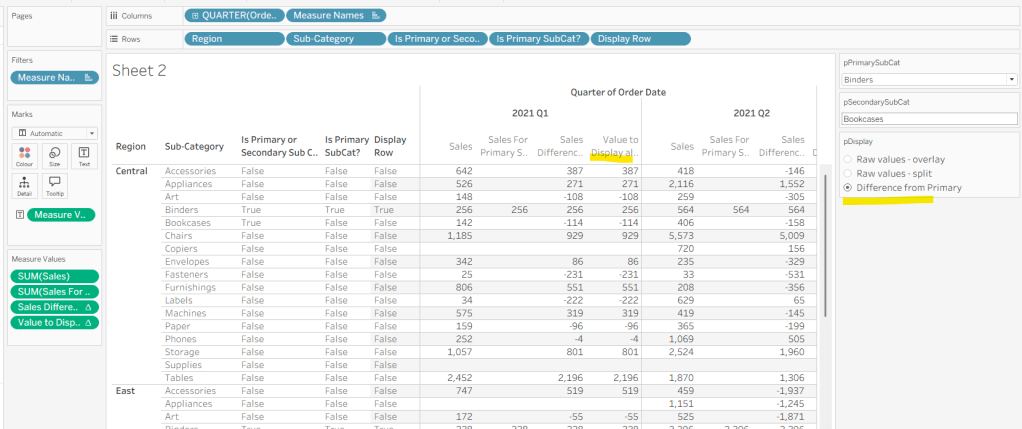
As I often do, we’ll build out a tabular display to determine all the calcs required. On a new sheet, add Region and Sub-Category to Rows, then add Order Date at the Quarter level as a discrete (blue) pill to Columns. Add Sales to Text. Show the 3 parameters created above.
We need to identify which Sub-Categories will be coloured. This is based on whether they are a primary or secondary Sub-Category.
Is Primary or Secondary Sub Cat
[pPrimarySubCat] = [Sub-Category] OR [pSecondarySubCat] = [Sub-Category]
Add this to Rows. Based on existing selections, the rows for Binders and Bookcases should be set to True.
We will also need to identify which is the the Primary Sub-Category only to help determine how many rows are displayed, so create
Is Primary SubCat?
[pPrimarySubCat] = [Sub-Category]
Add to rows. In this case just Binders should be True at this point.
With this field, we can then work out how many ‘rows’ are going to be in our final viz display.
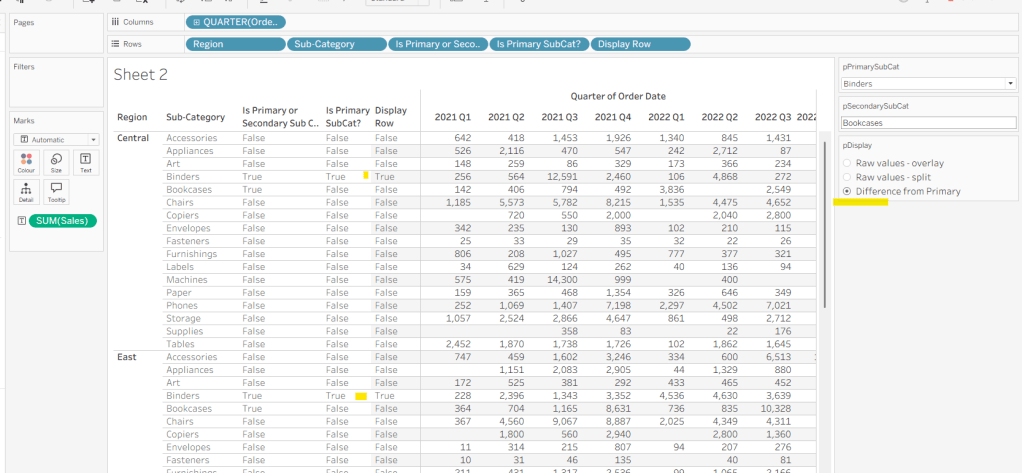
Display Row
IIF([pDisplay] = 0, TRUE, [Is Primary SubCat?])
ie, if the pDisplay parameter is ‘Raw values – overlay’ , then we’ll just display 1 row (so all rows set to True), otherwise there will be 2 rows, split based on whether the Sub-Category is the selected value in the pPrimarySubCat parameter or not.
Add this to Rows, and change the pDisplay parameter to see how this field changes.
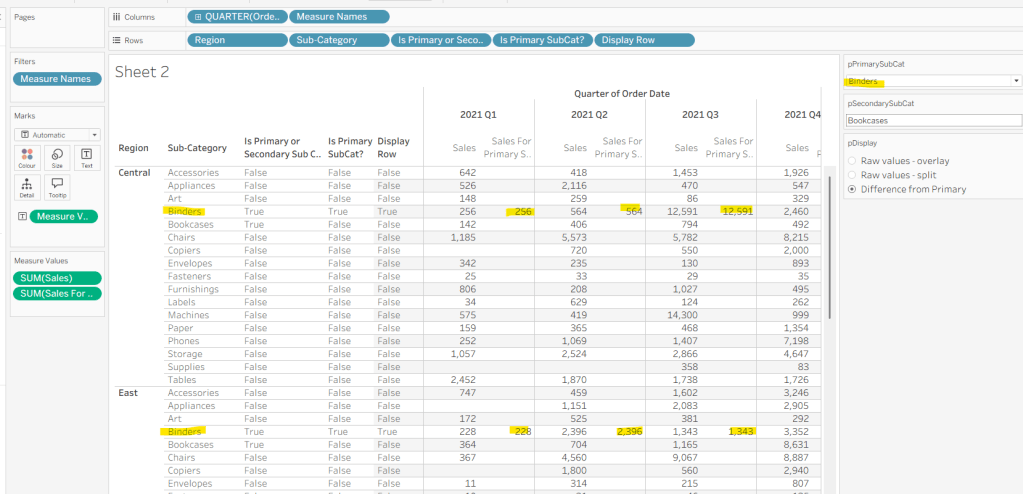
We also need to display different values depending on what pDisplay option is selected. When the ‘Difference from Primary’ option is selected, then we need to show the Sales value for theprimary Sub Category, but the difference from this value for all others. For this we first need to capture just the sales for the primary Sub-Category
Sales For Primary Sub Cat
IF [Is Primary SubCat?] THEN [Sales] END
Add to the table and adjust Measure Names so it is displayed after the Order Date field. Rows for this column will only have values when the Sub-Category is the primary one selected.
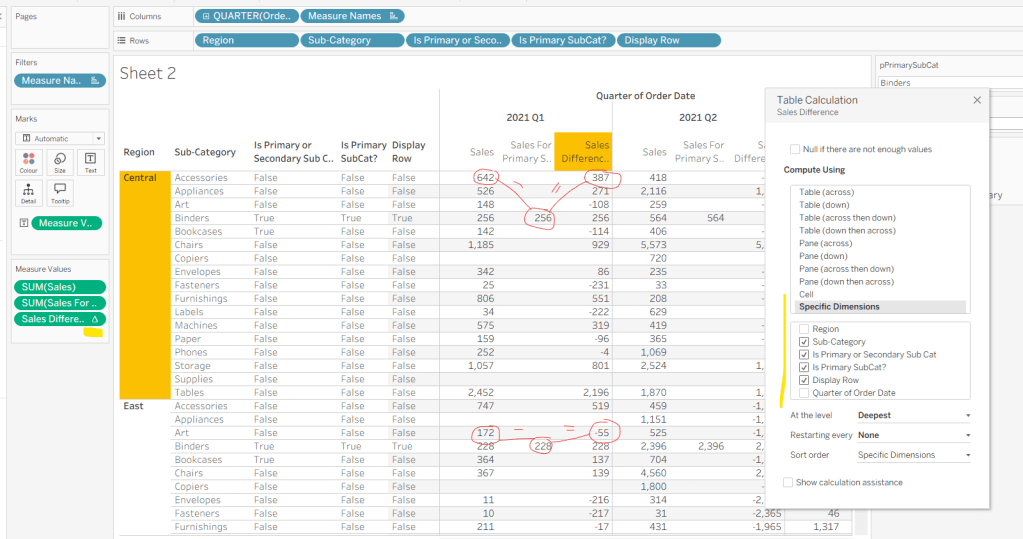
Now we calculate the difference, but only if it’s not the primary Sub-Category; we want Sales in that instance
Sales Difference
IF MIN([Is Primary SubCat?]) THEN SUM([Sales]) ELSE SUM([Sales]) – WINDOW_MAX(SUM([Sales For Primary Sub Cat])) END
Here we’re using a WINDOW_MAX table calc to essentially ‘spread’ the value in the Sales for Primary Sub Cat column across all rows associated to the Region. Add this to the table, and adjust the table calculation setting of the pill, so it is computing by all fields except Region and Order Date
Finally, we need a field that will decide whether we’re displaying Sales or Sales Difference based on the pDisplay selection
Again, add to the table, adjust the table calc as above and then test the output of the field, as you adjust the pDisplay parameter.
While we’re here, we’ll just define another couple of calcs needed for the viz
Label Sub Cat
IF [Is Primary or Secondary Sub Cat] THEN [Sub-Category] END
Used to only display a label for either of the two selected Sub-Categories.
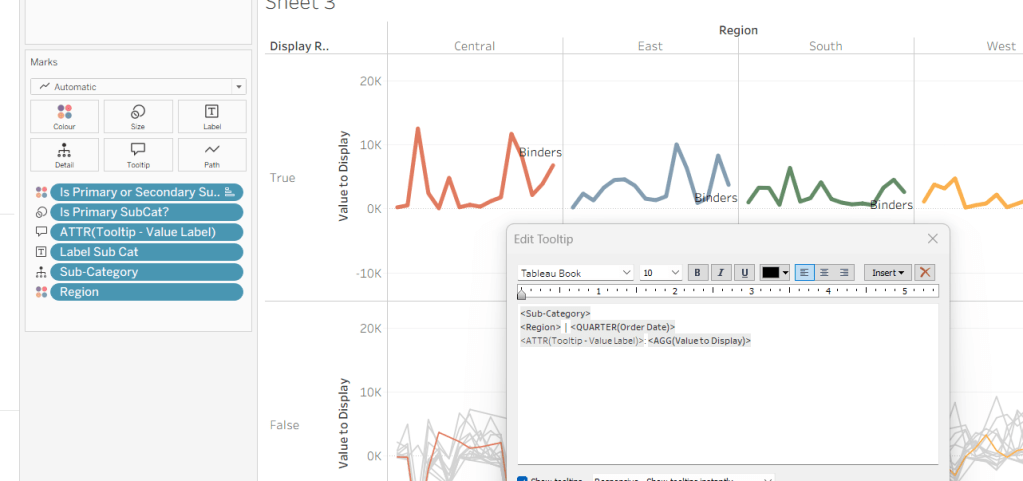
Tooltip – Value Label
IIF([pDisplay]=2 AND NOT([Is Primary SubCat?]), “Difference from ” + [pPrimarySubCat] + ” Sales”, “Sales”)
Will be used on the Tooltip to ensure the correct text is displayed depending on type of display selected.
Building the Viz
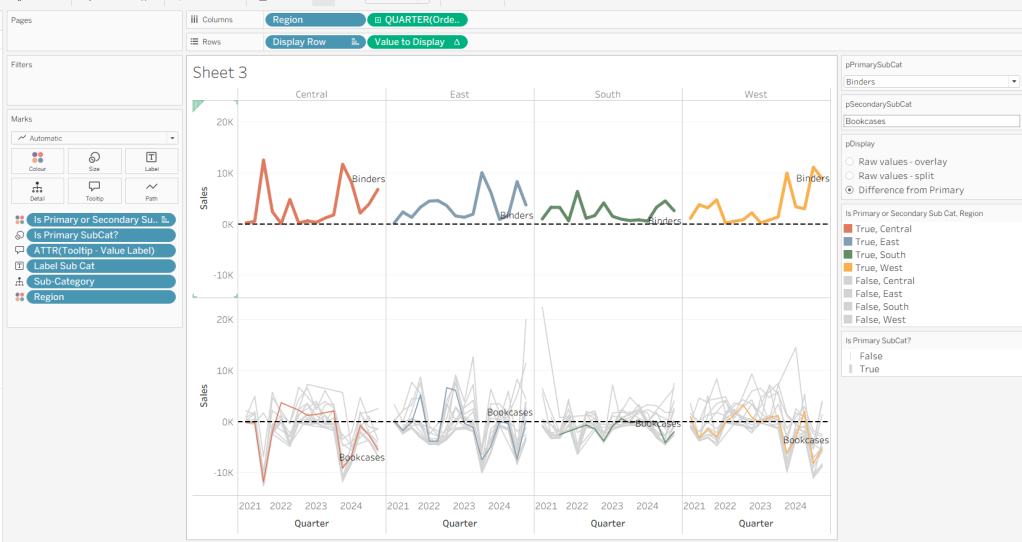
On a new sheet, show the 3 parameters and set them to the defaults (ie Binders, Bookcases and Difference from Primary).
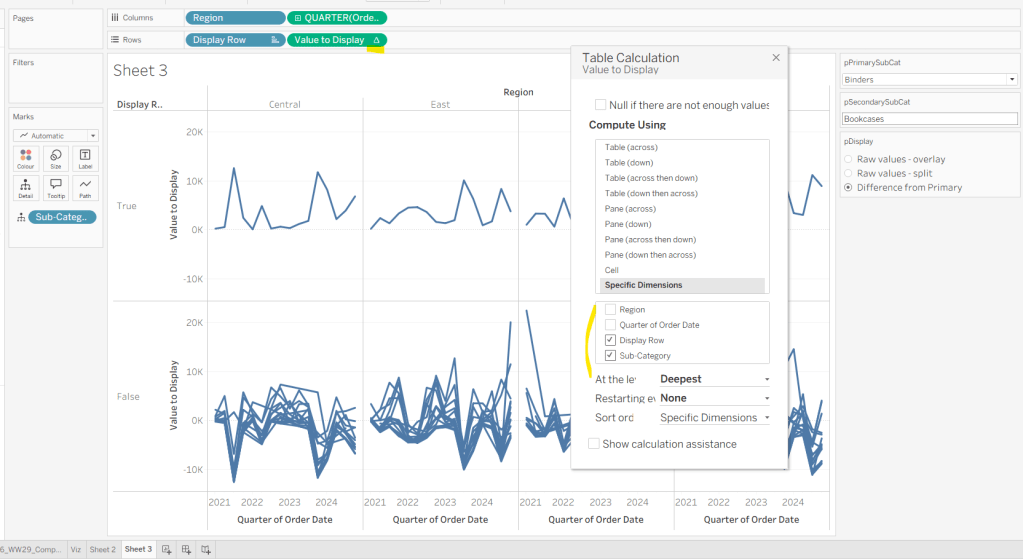
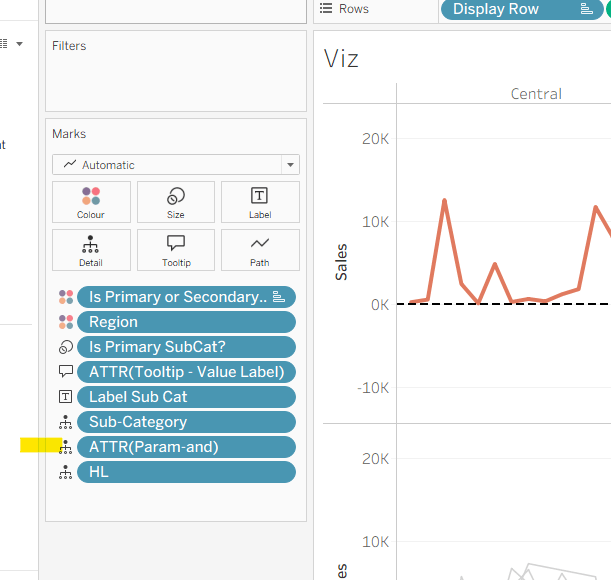
Add Region to Columns, then add Order Date at the Quarter level as a continuous (green) pill to Columns. Add Display Row to Rows and adjust the Sort on the pill to be a manual sort, where True is listed first. Add Sub-Category to Detail, then add Value to Display to Rows and adjust the table calc so all fields except from Region and Order Date are selected.
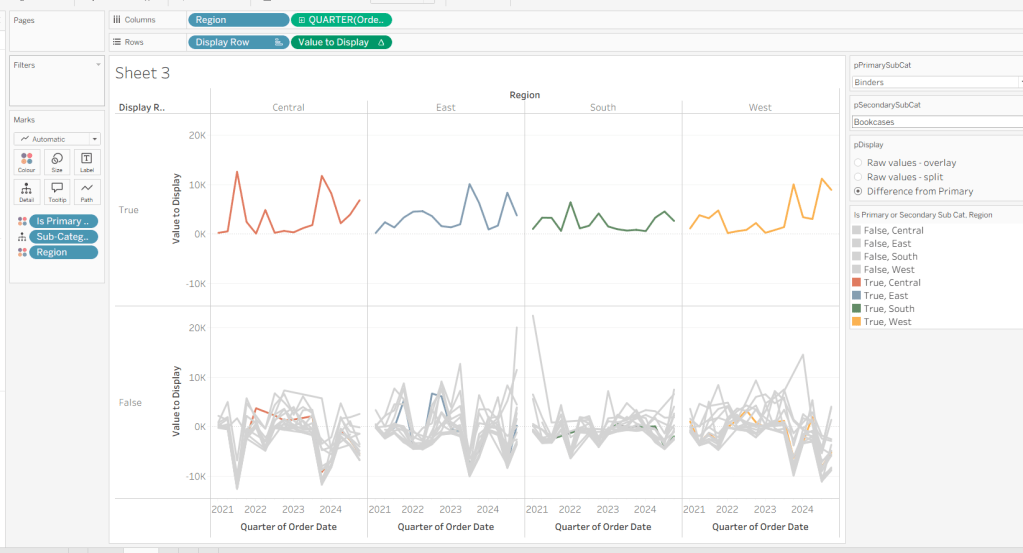
Add Is Primary or Secondary Sub Cat to Colour. Some lines will disappear, but don’t worry. Then add Region to Detail, and then select the ‘detail’ icon to the left of the pill on the marks shelf, and change it to Colour so 2 pills are now on the Colour shelf. Adjust the table calculation setting of the Value to Display pill to ensure the Is Primary or Secondary Sub Cat field is also now checked – this should make all the lines reappear.
Then adjust the colours in the colour legend so all the entries that start ‘False’ are grey and the others are as required.
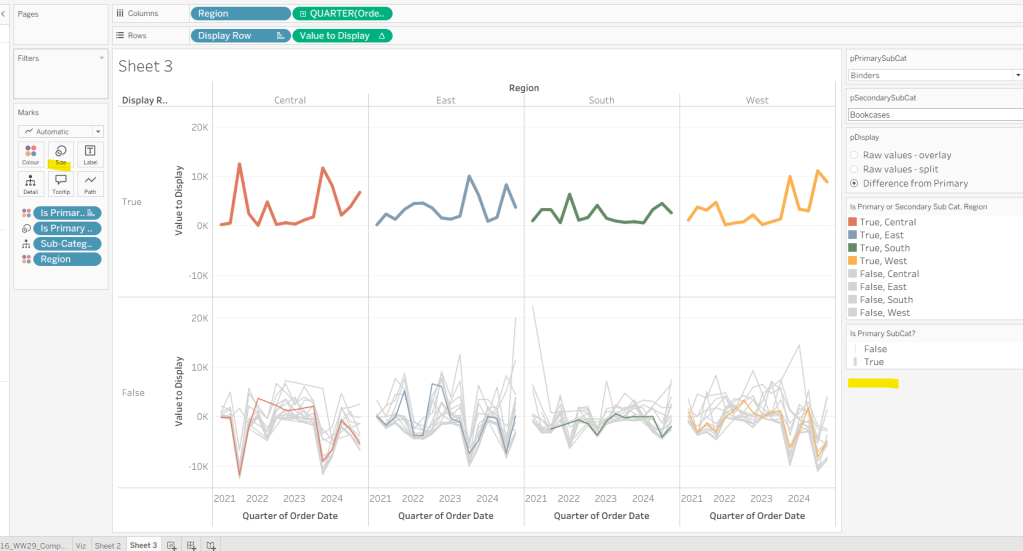
Adjust the sort on the Is Primary or Secondary Sub Cat pill on the marks card, so it is manually sorted with True first. This ensures the coloured lines are ‘on top’ and always visible. Add Is Primary SubCat? to Size shelf. Readjust the table calc on Value to Display again, and then adjust the Size so it is visibly thicker than the rest of the lines, which will probably be by adjusting both the range in the Size legend, and adjusting the slider on the Size shelf.
Add Label Sub Cat to the Label shelf (adjust table calc again), and set label to allow labels to overlap other marks. Add Tooltip – Value Label to tooltip and update the Tooltip as required
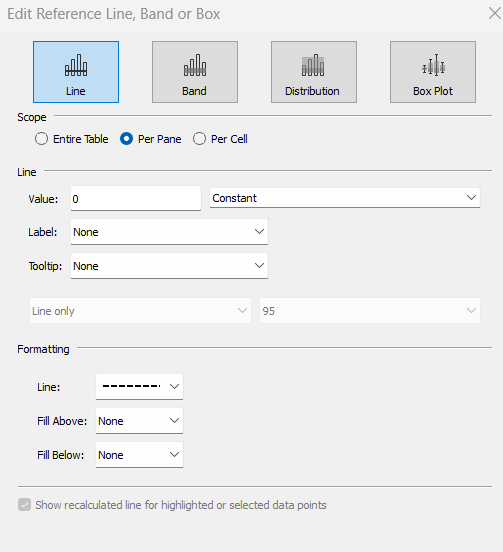
Add a reference line to the Value to Display axis, and set to be a constant of 0 displayed as a black dashed line
Edit both axis to update the axis titles on each, hide the Display Row pill (uncheck show header on the pill) and hide the Region column label (right click > hide field labels for columns).
Building the dashboard
Use layout containers to construct the dashboard as required
Create a dashboard parameter action to capture the value of the secondary Sub-Category
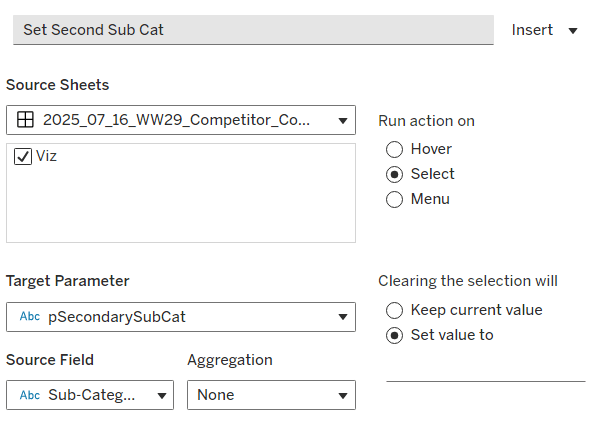
Set Second Sub Cat
On select of the Viz, set the pSecondarySubCat parameter with the value sourced from the Sub-Category field. When selection is cleared, set it <none>
Clicking one of the grey lines should now change the comparison Sub-Category. But you’ll notice the rest of the unselected lines are ‘faded’ and your selection is ‘highlighted’. We don’t want this to happen. To resolve, create new calculated field
HL
‘Dummy’
and add to the Detail shelf on the viz sheet itself.
Then add a dashboard highlight action
Un-Highlight
On selection of the Viz sheet on the dashboard, target the viz sheet on the dashboard, selecting the HL field only.
As all the marks have the HL ‘dummy’ field associated to them, they all become ‘highlighted’, giving the appearance of nothing actually being highlighted.
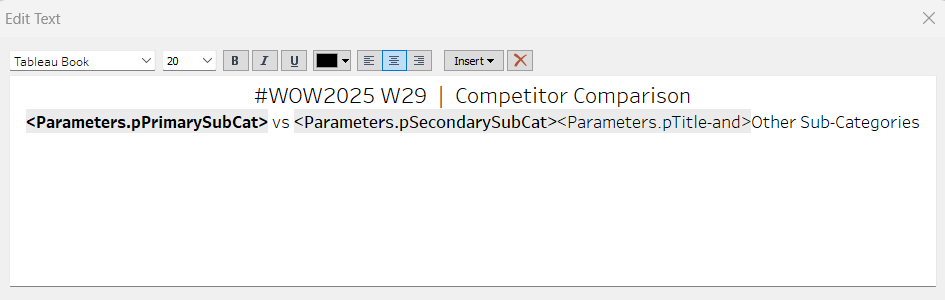
Finally, we need to make the title of the dashboard ‘dynamic’ and reflective of the selections made in the primary and secondary Sub-Category parameters. But the secondary one can be empty, so the text needs to handle this. An additional ‘ and ‘ needs to display if the secondary Sub-Category is set. I chose to use a parameter to help with this, as text objects on a dashboard can reference parameters.
Create a new parameter
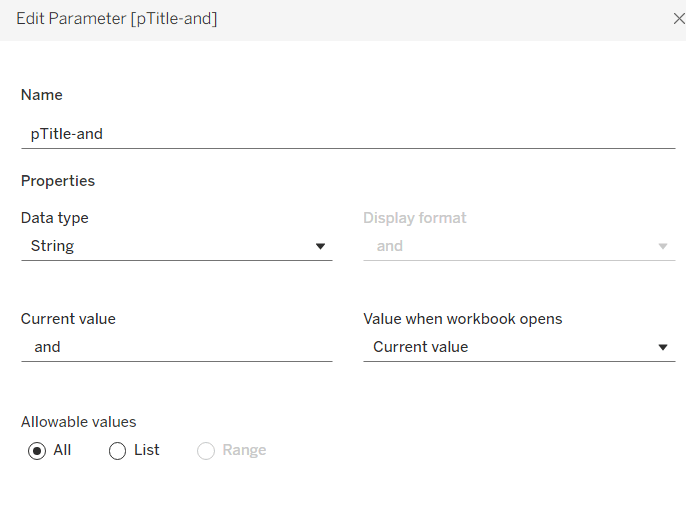
pTitle-and
string field defaulted to the text <space>and<space>
Create a calculated field
Param-and
‘ and ‘
and add to the Detail shelf on the viz. Set it to be an attribute (this won’t impact the table calc).
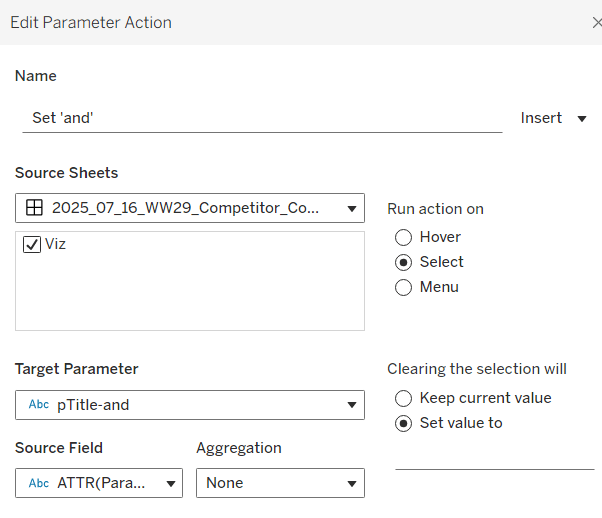
Back on the dashboard, create another dashboard parameter action
Set ‘and’
on select of the Viz, set the pTitle-and parameter passing in the value from the Param-and field. When the selection is cleared, set to <none>.
Then create (or adjust) the title text object so it references the relevant parameters (notice the spacing – or lack of – between some of the fields)