Erica set the challenge this week, which involved building the same visualisation in two ways – one using Table Calcs only and one using LODs.
To test the functionality and validate what’s going, I’m going to build the data out in a tabular format first.
The Table Calc Table
On a new sheet add Region and Category to Rows and Sales to Text. Sort by Sales descending. Then add Region and Segment to Filter, selecting all options, and show the filters.
Create a new field
Total Sales
TOTAL(SUM([Sales]))
and add into the table. This won’t be used later, but I’ve created so you can see the filtering behaviour.
This is a table calculation, and, by default when added to the table, it shows the total of all the rows against each row. We want to display the total per Region, so every row for a specific region shows the total of that region only. Adjust the table calc setting so it is computing by Category only.
Create a new field
TC – % of Sales
SUM([Sales]) / TOTAL(SUM([Sales]))
format to be % with 1dp and add into the table. By default it should have inherited the table calc settings we just applied for Total Sales, but if not apply the same settings, so it is computing by Category only.
If you do the maths taking the value in the Sales column and dividing by the value in the Total Sales column, you should be able to validate the result.
And if you test by adjusting the Segment and Region filters, everything should work as expected :
Filter out a Segment and the Sales and Total Sales adjust to exclude the value and the TC – % of Sales for a Region still totals 100%
Filter out a Region and that whole block is removed, but the values for all the other rows remain unchanged.
Now add Category to Filter and show the filter. Filter out a Category, and what we now see is the Total Sales now just reflects the total for the selected categories, and the TC – % of Sales still totals 100%. This isn’t the requirement. The % of Sales needs to calculate over all Categories regardless if it is excluded in the display.
To handle this, we create
TC – Filter Category
LOOKUP(MIN([Category]),0)
This is using a table calculation to basically return the value of the Category associated to the current row, which is basically looking up itself. However, as this is a table calculation, when added to the Filter shelf, it applies the filter after other computations (this is Tableau’s order of operations’), whereas the ‘quick filter’ applied above, is filtering the data first before then computing the total sales.
Remove Category from the Filter shelf, and add TC – Filter Category to the Filter shelf instead, selecting all options and showing the filter on the view. By default the table calc setting is set to table down which is fine – it is computing by both Region and Category. Now if you exclude a Category, the relevant rows disappear, but the Total Sales and therefore TC – % of Sales values remain unchanged.
The Table Calc Viz
The simplest way to build this (IMO) is to duplicate the table sheet then
Remove Total Sales and Sales
Move TC – % of Sales to Columns
Show mark labels
Adjust colour of bar
Adjust colour of worksheet background
Widen each row slightly
Make the width of bars slightly smaller
Edit title of % of Sales axis
Adjust fonts of label headers and bar label and axis labels (I set to 8pt)
The LOD Table
Let;s repeat this now using LODs instead.
On a new sheet, once again add Region and Category to Rows and Sales to Text. Add Region and Segment to Filter and show the filter options.
Create a field
LOD – Sales per Region and Segment
{FIXED [Region], [Segment]:SUM([Sales])}
Add into the table. With all segments selected, we can see the total sales for each Region listed
and filtering out a Segment, the totals adjust as required.
If we now add Category to Filter, show the options and filter one out, the totals now no longer change, as the LOD – Sales per Region and Segment doesn’t include Category in its definition – its FIXED to just account for changes to Region and Segment.
So we can now create
LOD – % of Sales
SUM([Sales]) / SUM([LOD – Sales per Region & Segment])
and format to % with 1dp and add into table to validate.
You can now apply similar steps to those detailed above to recreate the bar chart viz for this data.
And once done, add both charts onto a dashboard with their relevant filters.
This week, Kyle set the challenge of recreating area charts combined with a tile map / small multiple. He’d been inspired by a viz he uses at work, which he then realised had actually been inspired by a previous #WorkoutWednesday challenge from 2020 which I actually blogged about here.
So some of the steps for this solution guide, I’ll lift from my existing blog :-), but there are no table calcs in this instance.
Building the basic tile map
As per Kyle’s instructions, I started by building a new field that I could then format to millions
Pop
[Population (Population)] * 1000
I formatted this to be a custom number with 2 dp and displayed with Millions unit.
Put this into a table where State and Date on Rows and Pop on Text, just so we can validate what we’re up to…
We need to standardise/normalise the display, so the population for each State is ranging from 0 to 1. For this we need to determine
Min Pop Per State
{FIXED [State]:MIN([Pop])}
Max Pop Per State
{FIXED [State]:MAX([Pop])}
and we can then work out
Standardised Pop
(SUM([Pop]) – SUM([Min Pop per State]))/(SUM([Max Pop per State]) – SUM([Min Pop per State]))
Format this to display as a number with 2 dp. Add all 3 fields to the table. For each state the Standardised Pop should have a year when then value is 0 (equivalent to when the population is lowest for the state) and a year when the value is 1 (equivalent to when the population is highest for the state).
For the tile map, we also need fields Rows and Cols which are calculations that map each State to a number (and can be copied straight from the challenge sheet).
On a new sheet, add Rows to Rows (as a discrete dimension) and Cols to Columns (also as a discrete dimension). Add State to Detail. Your initial ‘map’ layout should start to take shape.
Add Date to Columns and set to be a the continuous Year level (green pill) and add Standardised Pop to Rows. Set the display to Entire View, so all the tiles are visible.
Change mark type to Area and add Pop to the Tooltip. Update the Tooltip as required.
Adding the State label and max value
For this we’re going to plot a single point that will be at the centre of the Date axis and slightly higher than 1. For this we need
This looks a bit complex, so I’ll break it down. What we’re doing is finding the number of years between the minimum year in the whole data set (1900) and the maximum year in the data set (2023). This is
We’re then halving this value ( /2) and rounding it down to the nearest whole number (FLOOR).
We then add this number of years to the minimum date in the data set (DATEADD), to get our central year – 1961.
Now we need a point where we can plot a mark against that date. It needs to be above the maximum value in the area chart (which is 1). Based on what I did before, I decided 1.75 worked
Plot State Label
IF YEAR([Date]) = YEAR([Centre Date]) THEN 1.75 END
Add Plot State Label to Rows between Rows and Standardised Pop. Change the mark type of this axis to shape and use a transparent shape (see here for info). Note you can use a circle and reduce size to smallest and opacity to 0% if you wish. However, this will show a small dot when hovering, which you don’t get with a transparent shape.
Add Max Pop per State to Label and change State from Detail to Label. Adjust the Label accordingly
Remove all text from the Tooltip dialog of the Plot State Label marks card, and hide the Nulls indicator label. Make the chart dual axis and synchronise the axis. Remove Measure Names from the All marks card.
Then remove all gridlines, zero lines, axis lines and row/column dividers. Hide all the axis and the Cols and Rows pills (uncheck show header).
Building the bar chart
Create a new field
Latest Pop per State
IF [Date] = {FIXED [State]:MAX([Date])} THEN [Pop] END
If the date is the maximum date for the state, then get the population. Format this to be 2dp in Millions.
Add State to Rows and Latest Pop for State to Columns and sort descending. Adjust the colour to suit. Show mark labels, and remove all gridlines etc and row/column dividers and hide the axis. Adjust the Tooltip.
Creating the highlight action
Add the two sheets to a dashboard. Add a dashboard highlight action
Highlight State
On hover of the bar chart, target the map, via the State field only.
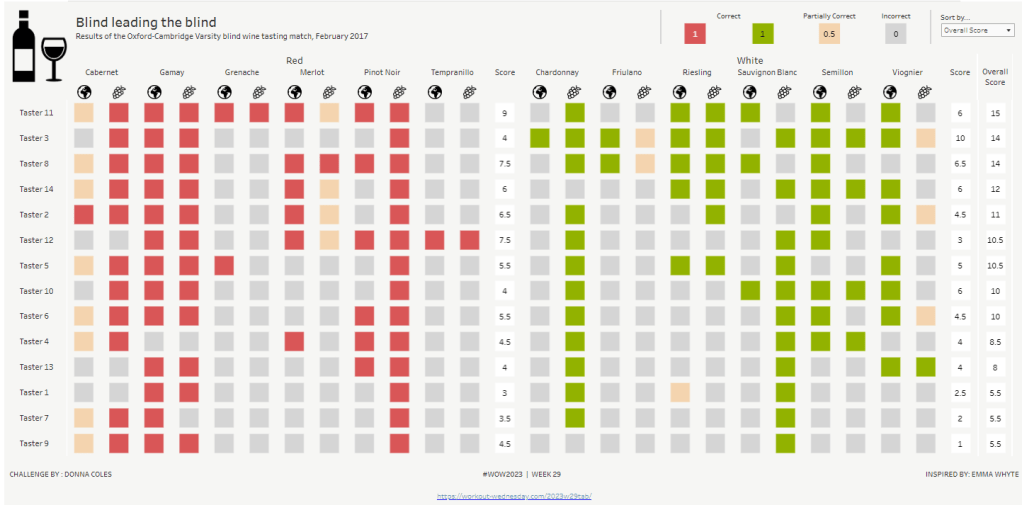
This week, it was my turn to set the #WOW2023 challenge for ‘retro’ month, and I chose to revisit a challenge from May 2017, that was originally set by one of the original ‘founders’ of WorkoutWednesday, Emma Whyte.
The original challenge looked like this :
As I said in the challenge post, I chose this I this challenge as it’s a different type of visual we don’t often see in WOW; it uses a different dataset that interests me – wine!; and as Emma’s website, where she hosted the original requirements for her challenges, is no longer active, it’s possible many won’t know of the existence of this challenge (it pre-dates the current WOW tracking data we have).
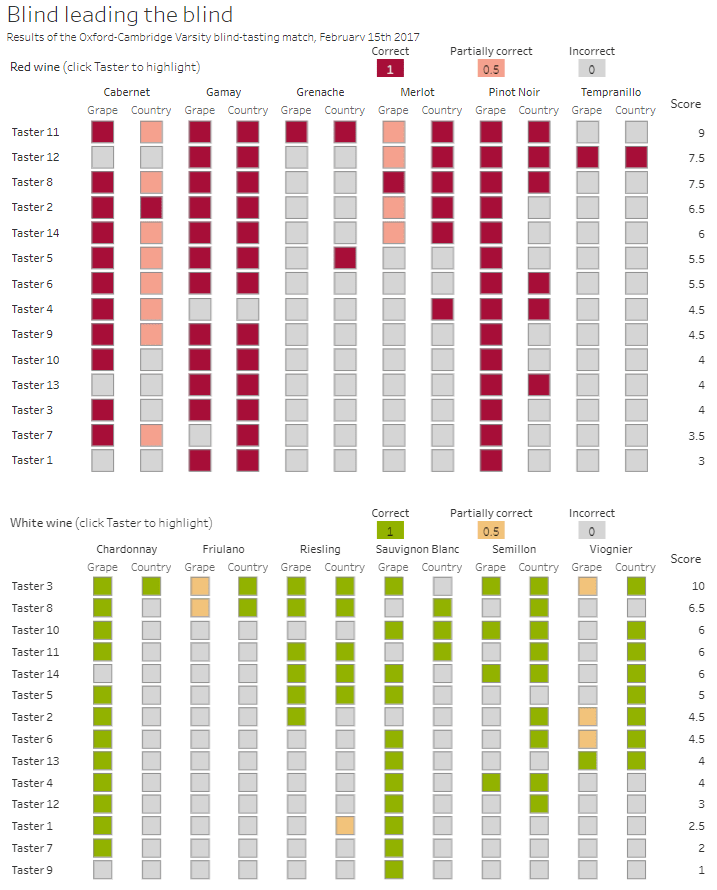
Building the core viz
Firstly, we want to build out the basic grid. For that we need a couple of calculated fields
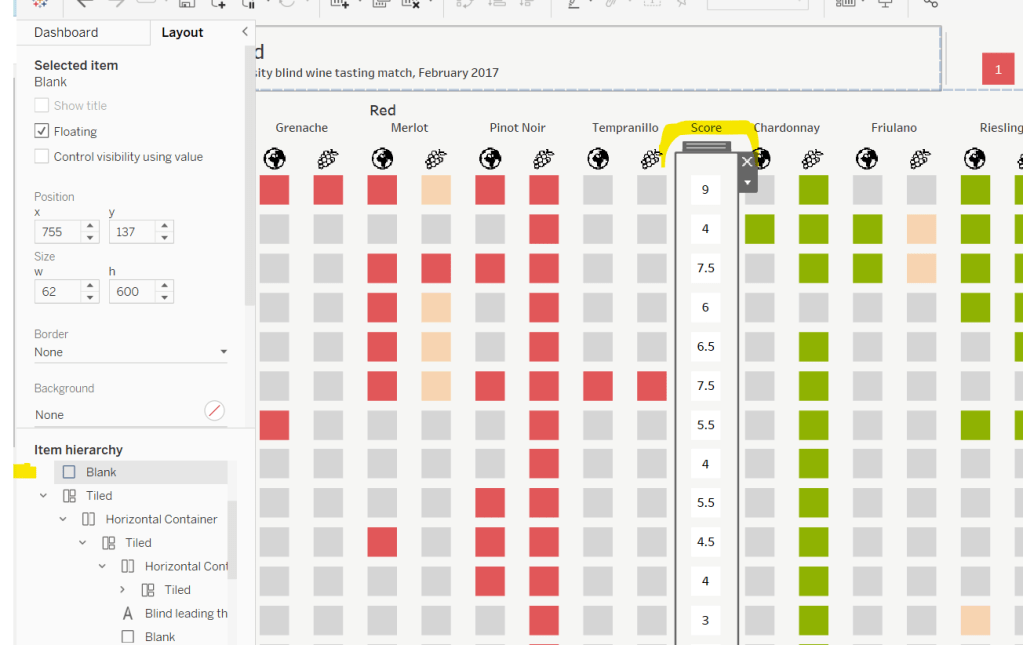
Right click on the Icon field and select Image Role > URL
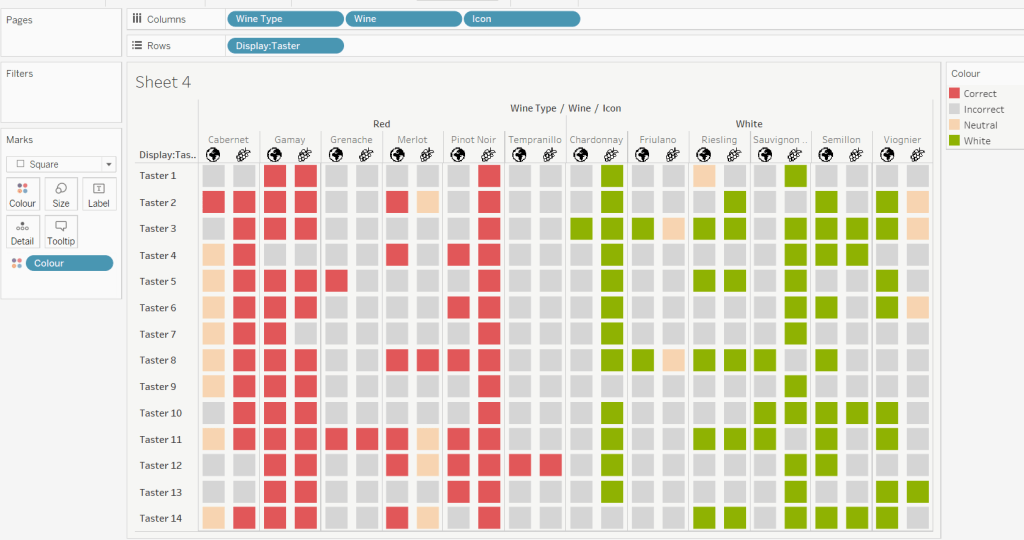
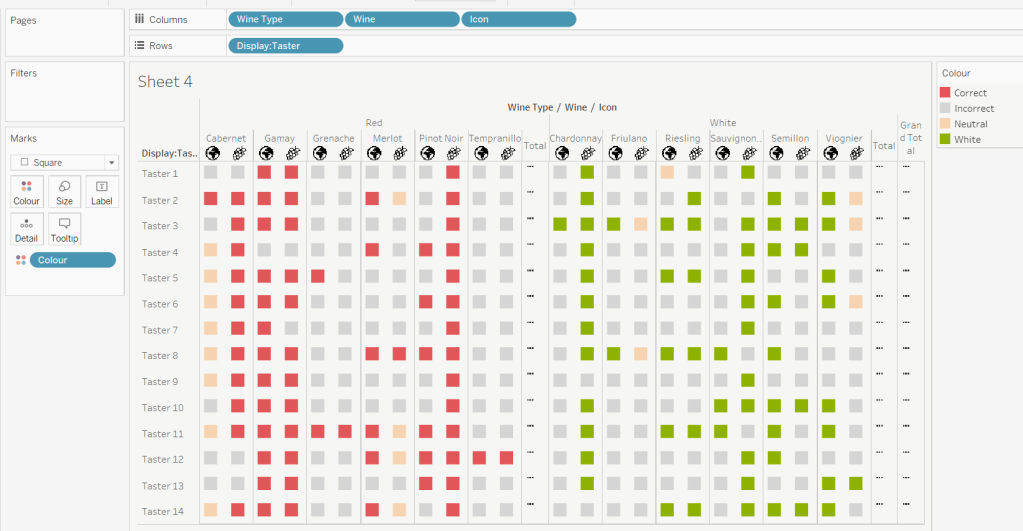
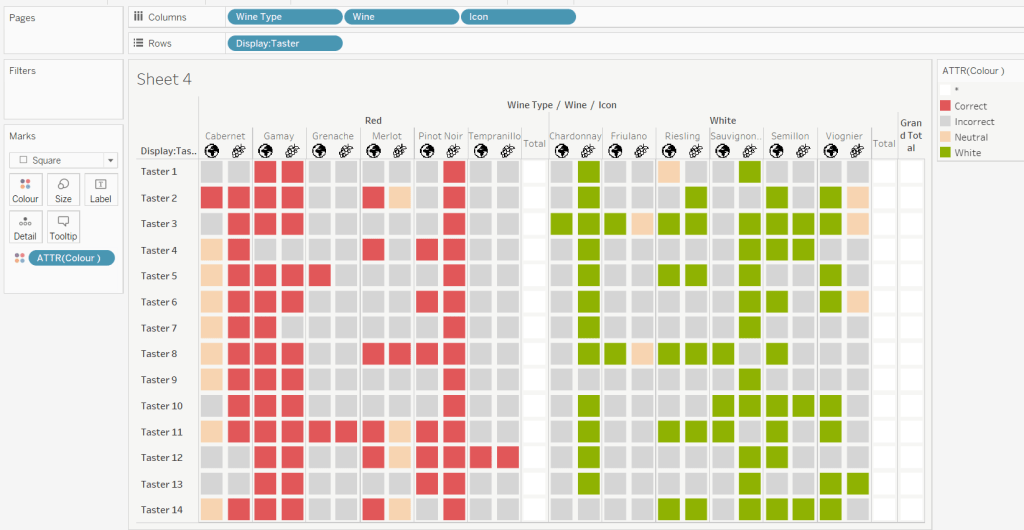
Add Wine Type, Wine and Icon to Columns and Display:Taster to Rows
Change the mark type to square.
Here we’re making use of the image role functionality in the header of the table to display images stored on the web, without the need to download them locally.
Create a new field
Colour
IF [Score] = 1 THEN [Wine Type] ELSEIF Score = 0 THEN ‘Grey’ ELSE ‘Neutral’ END
Add this to the Colour shelf and adjust colours accordingly. Increase the size of the squares so they fill the space better, but still have separation between them.
Set the background colour of the worksheet to the grey/beige (#f6f6f4).
Note – I noticed later on that the colour legend in the screen shots has the words ‘correct’ and incorrect’ rather than ‘red’ and ‘grey’. This was due to an un-needed alias I had set against the field, so please ignore
Via the Analysis -> Totals menu, add all subtotals & also show row grand totals. This will make the display look a bit odd initially.
Right-click on the Wine pill in the Columns and uncheck the Subtotals option. This should mean there are 3 additional columns only – a total for each wine type and the grand total.
To get a single square to display in the totals columns, right-click on the Colour field in the marks card area, and change from a dimension to an attribute. The field will change from displaying Colour to ATTR(Colour) and an additional option for * will display in the colour legend – set this to be white
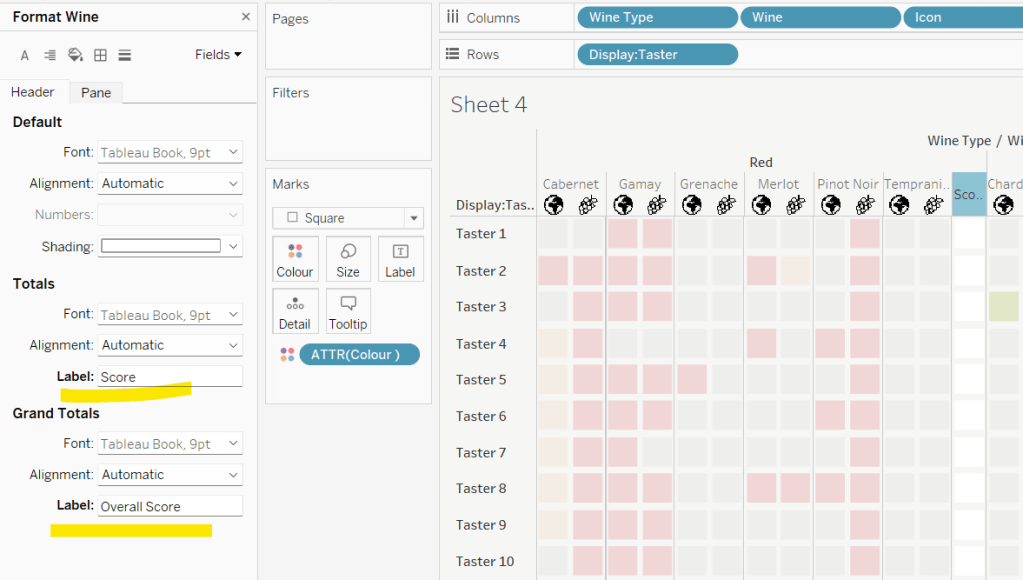
To change the word ‘Total’ in the heading to ‘Score’, right click on the word ‘Total’ and select format. In the left hand pane, change the Label of the Totals section to Score. Repeat for the ‘Grand Totals’ by right clicking on ‘Grand Totals’ in the table, selecting format and changing the label for that too to ‘Overall Score’.
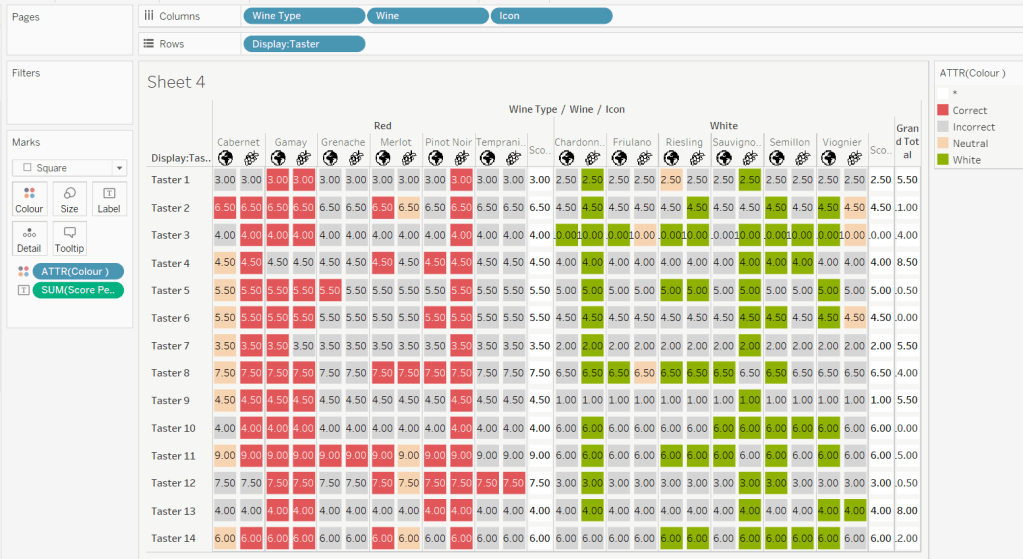
We need to label the totals with the score. For this we first need to get a score for each taster per wine
Score Per Taster
{FIXED [Taster], [Wine Type]:SUM([Score])}
If we just added this to the Label shelf, every square gets labelled with the total, which isn’t what we want.
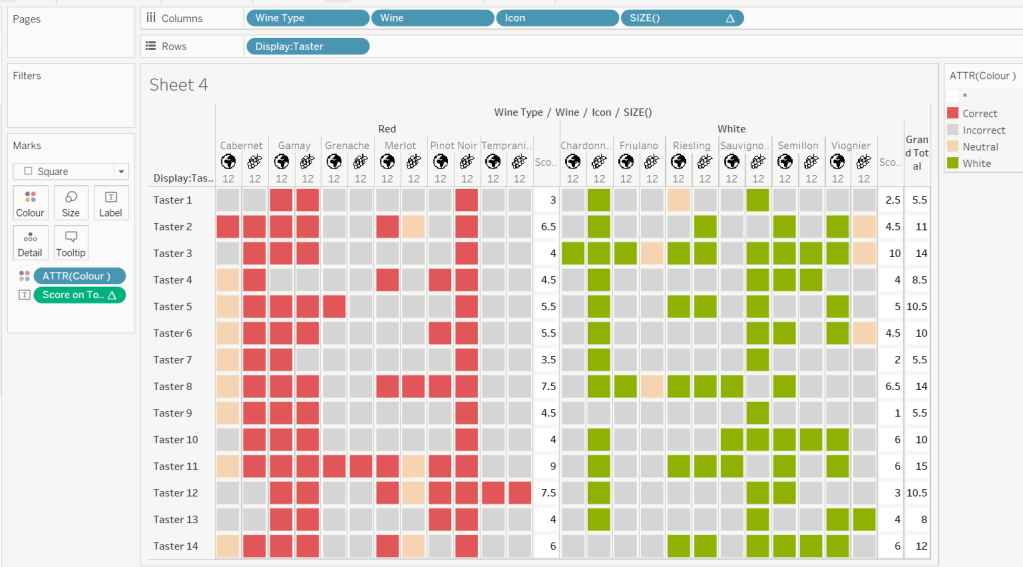
We need to work out a way to just show the label on the total columns only. For this we can make use of the SIZE() table calculation.
To see how we’re going to use this, double click into the Columns and type SIZE(), then change the field to be a blue discrete pill. Edit the table calculation and set the field to compute by Wine and Icon only.
You’ll see that the SIZE() field in the Columns has added the number 12 as part of the heading, which is the count of wines associated to the wine type (ie 12 red wines and 12 white wines). There is no SIZE() value displayed under the total columns, but these actually have a size of 1, so we’re going to exploit this to display the labels (note – this approach wouldn’t work if where was only 1 wine for one of the wine types).
Score on Total
IF SIZE() = 1 THEN SUM([Score Per Taster]) END
Set the default number format of this field to be Standard, which means the result will display either whole or decimal numbers.
Add this onto the Label shelf instead of the other field, and adjust the table calculation as described above to compute by Wine and Icon only.
You can now remove the SIZE() field from the Columns.
Align the scores centrally.
Remove row & column dividers from each cell, and the totals, but set a white column divider for both the pane & header of the Grand Total column.
Format the text for the Wine Type and Wine and Totals fields. Align the text for the Wine field to the Top.
Hide field labels for rows and columns.
Applying the Tooltip
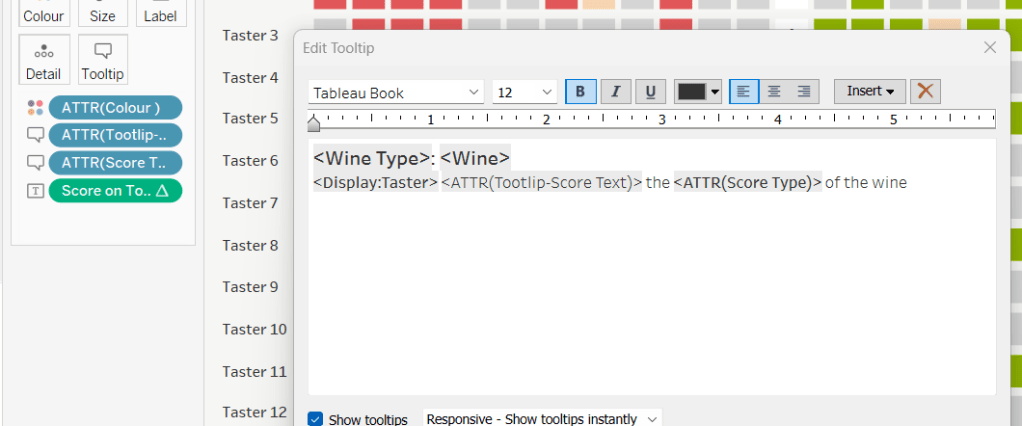
The text when hovering over each square needs to display different wording depending on the score.
Tooltip – Score Text
IF [Score] = 1 THEN ‘correctly identified’ ELSEIF [Score] = 0.5 THEN ‘partially identified’ ELSE ‘was unable to identify’ END
Add this to the Tooltip shelf along with the Score Type field. Modify the text accordingly
Applying the sort
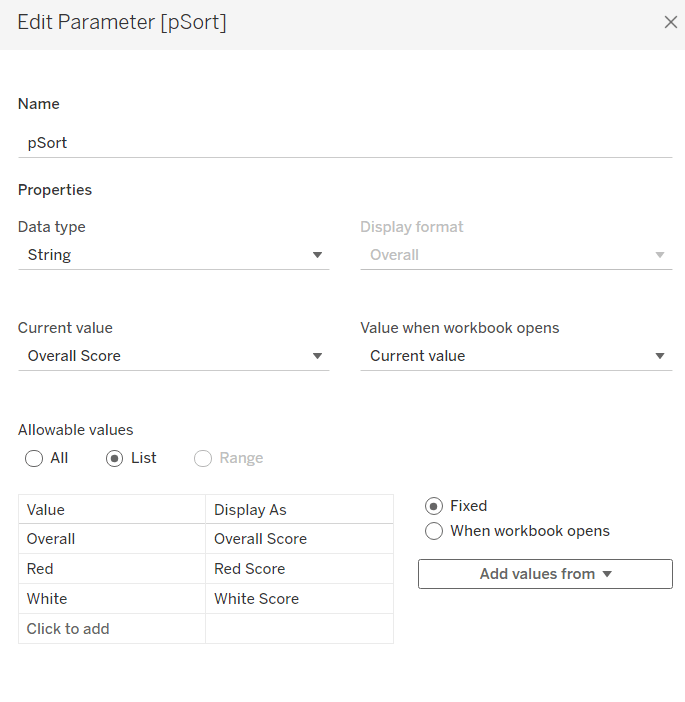
To control the sorting, we need a parameter
pSort
string parameter with list options, defaulted to ‘Overall Score’
and we also need fields to capture the different scores for each type of wine per taster
Red Score
{FIXED [Taster]:SUM( IF [Wine Type] = ‘Red’ THEN [Score] END)}
White Score
{FIXED [Taster]:SUM( IF [Wine Type] = ‘White’ THEN [Score] END)}
Overall Score
[White Score] + [Red Score]
Then we need a calculated field to drive sorting based on the option selected and the fields above
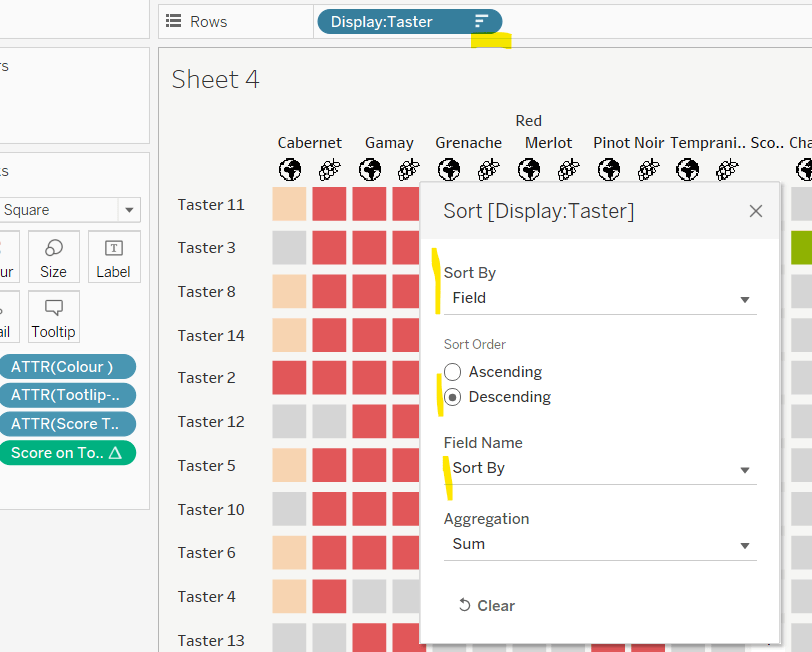
Sort By
CASE [pSort] WHEN ‘Overall’ THEN [Overall Score] WHEN ‘Red’ THEN [Red Score] ELSE [White Score] END
Then right click on the Display:Taster field on the Rows and select Sort, and amend the values to sort by field Sort By descending
Building the legend
I did this using 2 sheets. First I created a new field
Legend Text
IF [Score] = 1 THEN ‘Correct’ ELSEIF Score = 0 THEN ‘Incorrect’ ELSE ‘Partially Correct’ END
Then I create a viz as follows
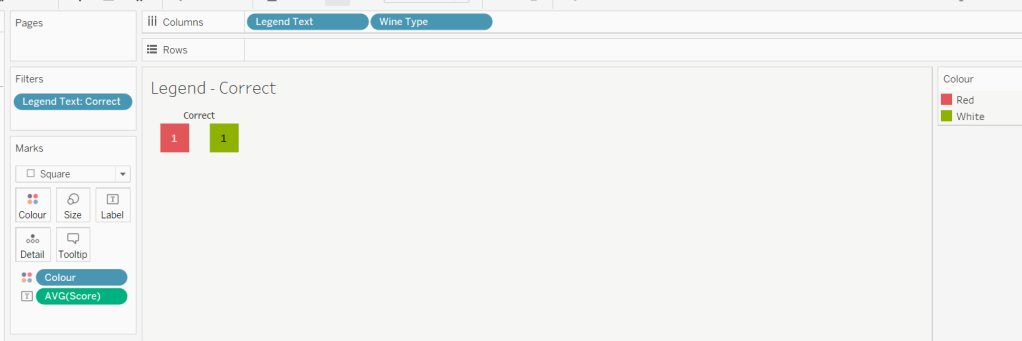
Add Legend Text and Wine Type to Columns
Add Legend Text to Filter and set to ‘Correct’
Change Mark type to Square and increase size
Add Colour to Colour shelf
Add Score as AVG to Label and format to number standard. Align centrally
Uncheck show header against the Wine Type field , and hide field labels for columns against the ‘legend Text’ column heading.
Remove all column/row dividers and set the worksheet background colour.
Turn off tooltips
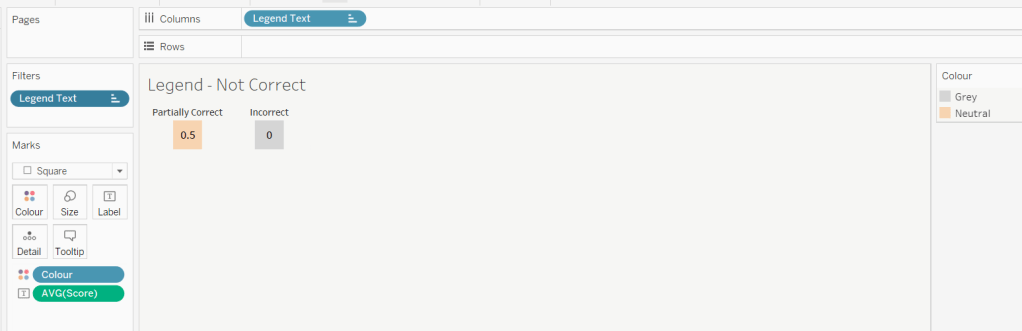
Duplicate the sheet, and edit the filter so it excludes Correct instead. Remove Wine Type from the columns shelf. Reorder the columns.
Building the dashboard
When building the dashboard, I just used a floating image object to add the bottle & glass image in the top left of the dashboard.
I set the background colour of the whole dashboard to match that I’d set on the worksheets too.
To stop the tooltips from displaying when hovering over the Scores, I simply placed floating blank objects over the score columns – this is a simple, but effective trick – you just need to be mindful of the placement if you ever revisit the dashboard and move objects around. I placed a floating blank over the legends too to stop them being clicked on.
It was Candra’s turn to ‘set’ the #WOW2021 challenge this week providing a hint in the challenge description that the solution would involve sets.
As with many challenges, I built the data out in tabular format to start with to verify I had all the components and calculations correct. The areas of focus are
Identify number of distinct customers per product
Identify overall average number of distinct customers per product
Identify if product above or below average distinct customers
Identify Top 50 products by Sales
Identify Unprofitable Products
Identify products that are both in the top 50 AND unprofitable
Building the viz
Identify number of distinct customers per product
To start off, add Product Name, Sub-Category, Category to the Rows shelf to begin building out a table. Add Sales (formatted to $k 0dp) and Profit (formatted to $k 0dp with negative values as () ) to Text and sort by Sales descending.
To identify the distinct customers per product, we can create
Customer Count per Product
{FIXED [Product Name] : COUNTD([Customer ID])}
Add this to the view.
Identify overall average number of distinct customers per product
What we’re looking for here is the average of all the values we’ve got listed in the Customer Count per Product column. Ie we want to sum up those values displayed and divide by the number of rows.
The number of rows is equivalent to the number of products, which we can get from
Count Products
{FIXED : COUNTD([Product Name])}
And so to get the overall average we calculate
Avg Overall Customer Count
{FIXED: SUM([Customer Count Per Product])} / [Count Products]
Add these fields to the view as well, so you can see how the values work per row. The last two calculations give you the same value across all rows.
Identify if product above or below average distinct customers
Given the above display, this is just a case of comparing values in 2 columns
Higher than Avg Customer Count
AVG([Customer Count Per Product]) > SUM([Avg Overall Customer Count])
this returns true or false – add this to the view too.
Identify Top 50 products by Sales
We can create a set for this. Right click on Product Name > Create > Set. Name the set something suitable eg Top 50 Products, and on the Top tab, state the number (50) and the field (Sales) and the aggregation (Sum)
Add this to the view, and if you’ve sorted by the sales, you should find the top 50 rows are all In the set, and the rest are Out.
Identify Unprofitable Products
We can use another set for this. Again create a set off of Product Name, call it Unprofitable Products, and on the Condition tab, set the condition so that the Sum of Profit is less than 0
Add this onto the view too.
Identify products that are both in the top 50 AND unprofitable
For this, we’re explicitly looking for the rows that are both In the Top 50 Products set and In the Unprofitable Products set.
We can use the Combined Set functionality to do this.
In the left hand data pane, select both the Top 50 Products and the Unprofitable Products sets (hold down ctrl to multi select), then right click and Create Combined Set. I called the set Products to Include, and select to combine the sets by including Shared members in both sets
If you then add this field to the Filter shelf, you will be left with just the 13 Products that match
This is the single filter field you can use as per Candra’s requirements.
Building the viz
To get the text to display to the left of the bar, you actually need to create a ‘fake’ bar chart.
Add Products to Include to Filter
Add Product Name to Rows
On the Columns shelf, double click and type in MIN(1)
Add Sales to Columns to the right of MIN(1)
Sort by Sales descending
Against the MIN(1) marks card
Change the Size to small
Set the Opacity of the Colour to 0% and the border to None
Add Product Name, Sub-Category and Category to the Label shelf and adjust accordingly, aligning left
Increase the height of each row to make the text visible
On the Sales marks card
Add Higher than Avg Customer to the Colour shelf and adjust
Show mark labels
Create a new field Profit Ratio : SUM([Profit])/SUM([Sales]) Format to % with 0dp and add to Tooltip
Add Profit, and Customer Count by Product to Tooltip and adjust accordingly
Finally, uncheck Show Header against Product Name and MIN(1) and Sales and format the borders/gridlines etc. Add the title, then add to the dashboard.
For week 17 of #WOW2021, Sean Miller decided to challenge us with recreating a chart by Nathan Yau (see here for the original). The aim was to recreate within 1 sheet, which I managed to do. So how did I do it? Read on 🙂
The groundwork
Colouring the bars
Adding the year labels
Final formatting
The groundwork
The chart itself follows a straight forward structure of multiple blue dimension fields on Columns with a green measure on Rows similar to this view below based on Superstore Sales data – it’s just formatted a bit more creatively!
The data provided just contains 3 fields : SEX, AGE and 2019 Population. We want to present the 2019 Population measure for the Total SEX only by Year. We need to create the Year field, which is simply
Year
2019-[AGE]
I dragged this into the ‘dimensions’ section of the data pane (above the line).
This allows us to create the basic bar chart required
We now need to define the various fields that we will need to add as additional dimensions on the Columns shelf to create the ‘generation’ data panes.
Generation
IF [Year]<= 1927 THEN ‘Greatest Generation’ ELSEIF [Year]<= 1945 THEN ‘Silent Generation’ ELSEIF [Year]<=1964 THEN ‘Baby Boomer’ ELSEIF [Year] <= 1980 THEN ‘Generation X’ ELSEIF [Year]<=1996 THEN ‘Millennials’ ELSEIF [Year]<=2012 THEN ‘Generation Z’ ELSE ‘Gen Alpha’ END
NOTE – there is a deliberate carriage return in the condition for ‘Greatest Generation’ and ‘Gen Alpha’ which will force the field to ‘wrap’ when displayed.
SUM([Total Population Per Generation]) / TOTAL(SUM([Total Population Per Generation]))
NOTE – to create this field, I originally created a ‘quick table calculation’ against the Total Population Per Generation field which I’d displayed on a view, and then dragged the resulting pill into the measures pane to create the new field with the desired calc.
Let’s put these in a table, so we can then check the values, and see that the 2nd and 3rd columns are the same value for each row associated to a particular generation, which is what we need.
Right, so now we need to determine the rank based on the Total Population Per Generation
Rank
RANK_DENSE(SUM([Total Population Per Generation]))
Format this to a custom number with 0 decimal places, but prefixed with #
When added to the table we get
The intention, is that Rank will be displayed as discrete ‘header’ pill rather than a measure, so let’s move Rank to be the 1st pill on the Rows shelf and change to be discrete.
But we need the Total PopulationPer Generation and % of Total Population fields to be combined into a single pill. So we need to do a bit of string manipulation/ number formatting for this
Total | Percent
STR(ROUND(SUM([Total Population Per Generation])/1000000,1)) + ‘M’ + ‘ | ‘ + STR(ROUND([% of Total Population] * 100,1)) +’%’
This looks complicated, but its because even though you may have applied the relevant display number formatting against the individual numeric measures of Total PopulationPer Generation and % of Total Population, the formatting is not preserved, when converted into a string field, which this field needs to be. So the relevant calculations need to be applied within the field itself.
This outputs the below
Now we need a way to sort the data so the ‘Greatest Generation’ associated to the earliest years is listed first. I did this by determining the minimum date within each Generation.
Min Year Per Generation
{FIXED [Generation], [SEX]: MIN([Year])}
Add this into the view as the first pill in Rows, and the data should automatically sort from lowest to highest
We can now build the viz – duplicate the table sheet, remove Total Population Per Generation and % of Total Population from the Measure Values section. Drag 2019 Population to Columns, then click the swap rows & columns button :
Colouring the bars
The bars are coloured based on each ‘Generation’ pane. You could hardcode this along the lines of ‘Generation = x OR Generation = y or Generation = z etc’ where x, y and z etc are generations of the same colour. This would return true or false, which you can then add to the colour shelf and adjust accordingly.
I decided to be a bit more dynamic, deciding I wanted to set the colour based on whether it was an odd or even pane.
For this I created another ‘rank’ field based on the field I’d used to ‘sort’ the data, the Min Year Per Generation field.
Sort Position
RANK_DENSE(MIN([Min Year per Generation]),’asc’)
If you add this into the data table, you’ll see each section is numbered 1 -7
From this, we can then determine if the number is even (or not)
Sort Position is even number
[Sort Position]%2=0
Add this onto the Colour shelf which will return True or False and colour accordingly.
Adding the year labels
The year labels are achieved by using a dual axis chart, to plot a point for each specific year (based on the Min Year Per Generation field) at some arbitrary value.
Point to Plot Year Label
IF [Year]=[Min Year per Generation] AND [Year]<>1919 THEN 4700000 END
For each ‘min year’ that isn’t 1919, plot a value at 4.7M.
Add this field to the Rows shelf, change mark type to circle, reduce size to as small as it can, and set the colour transparency to 0.
Add Min Year Per Generation to the Label shelf, then change the alignment to vertical.
Now you make the chart dual axis and synchronise the axis. Some of the colours/marks may change, so reset by removing Measure Names from the Colour shelf and changing the mark types bar to bar & circle.
Final formatting
So at this point all the main components are there. It’s now a case of formatting – removing right and bottom axes, removing gridlines. The vertical dashed lines, are column dividers, set at the pane level only.
The solid left hand axis is set via
The text is formatted using the fonts advised in the requirements and sizes adjusted to suit.
Add on a tooltip, and set the background colour of the worksheet and you should be done.
It was Lorna’s turn to set the challenge this week, and she took the opportunity to ask us to use a new feature in Tableau v2021.1 – Quick LoDs (you’ll obviously need v2021.1 to use the functionality, but the LoDs can be created manually in earlier versions if need be).
This blog will focus on
Creating the Sub-Category Average Sales by Category LoD using Quick LoDs
Formatting the difference calculation
Colouring the bars
Text for Tooltip
Putting it all together
The viz itself isn’t that complex once you’ve nailed the LoD, so lets’ start with that bit.
Creating the Sub-Category Average Sales by Category LoD using Quick LoDs
The what…? It’s a bit of a mouthful,.. the “Sub-Category Average Sales by Category”. What we’re essentially after here is the Total Sales per Category / No of Sub-Categories in the Category. To do this with LoDs, we first need to create an LoD to represent the total sales in each Sub-Category.
As mentioned in the requirements / referenced in the KB article above, you use a combination of ctrl/command click & drag to create an LoD via the Quick LoD feature. In this case I dragged the Sales measure onto the Sub-Category dimension, and this automatically created
Sales (Sub-Category)
{ FIXED [Sub-Category]: SUM([Sales]) }
which is the sales per sub-category.
From this, I then dragged this measure onto the Category dimension, which automatically then created
Sales (Sub-Category) (Category)
{ FIXED [Category]: SUM([Sales (Sub-Category)]) }
BUT I then edited this to change the aggregation to AVG, so the field became
{ FIXED [Category]: AVG([Sales (Sub-Category)]) }
This gives the average value required, which you can see is the same across the rows in a single Category :
Formatting the difference calculation
The viz displays the % difference between the Sub-Category sales and the average. This is calculated with
This is then custom formatted as ▲0%;▼0% (I use this site to get my shapes from).
Colouring the bars
The bars need to be coloured based on the value of the Difference field, so another calculated field is required
Colour
[Difference]>0
This will just return true or false and can dropped on the Colour shelf of the bars.
Text for Tooltip
Within the tooltip, the % difference is displayed, along with some text which indicates if it is above or below the average. For this we need another calculated field to reference in the Tooltip.
Above | Below
IF [Difference]>0 THEN ‘Above’ ELSE ‘Below’ END
Putting it all together
With all the calculated fields built, the the chart itself is a relatively simple dual axis chart
Add Category then Sub-Category to Rows
Add Sales to Columns and sort descending
Add Sales (Sub-Category) (Category) to Columns. Make dual axis and synchronise axis
Click on the All marks card and remove Measure Names from the Colour shelf.
Click on the Sales marks card and change mark type to bar; add the Colour field to the Colour shelf and adjust accordingly; add Difference to the Label shelf and format appropriately.
Click on the Sales (Sub-Category)(Category) marks card and change mark type to Gantt; adjust the Size to be as large as possible; set the colour to the relevant grey.
On the All marks card, add the Above | Below field to the Tooltip shelf, then edit the Tooltip on the All marks card to create the required text.
Finally, remove axis, remove the column heading labels, remove grid lines and column borders and format the displayed text appropriately. Title the viz.
A very brief post today, but hopefully I’ve ticked off all the required elements, My published viz is here.
Ann Jackson challenged us this week to build this matrix depicting the average worth of customer cohorts during their lifetime.
This challenge involves a mix of LoDs (Level of Detail calculations) and table calculations.
First up , we need to define our customer cohorts (ie group the customers), which for this challenge is based on identifying the quarter they placed their first order in. This will involve an LoD calculation. For a good introduction to LoDs with some worked examples (including a similar cohort analysis example), check out this Tableau blog post.
The 2nd part of the formula in the { … } returns the earliest Order Date associated to the Customer ID, which is then truncated to the 1st day of the quarter that date falls in ie 23 Feb 2019 is truncated to 01 Jan 2019.
For the ‘quarters since birth’ field, we need to calculate the difference in quarters, between the ACQUISITION QUARTER and the ‘quarter’ associated to the Order Date of each order in the dataset.
Drag this field into the ‘dimensions’ area of the left hand data pane (above the line if you’re using later versions of Tableau).
Lets sense check what this looks like, by adding
ACQUISITION QUARTER to Rows (Discrete, Exact Date)
ORDER DATE to Rows, set to Quarter (quarter year ie May 2015 format which will make a green pill), then set to discrete to change to blue
QUARTERS SINCE BIRTH to Rows
You can see that while the first row against each cohort starts with a different quarter, the QUARTERS SINCE BIRTH always starts at 0 and counts sequentially down the table.
Next we want to count the number of distinct customers in each cohort, and we’ll use another LOD for this.
Once again move this field into the Dimensions section of the data pane.
Add this onto the Rows of the above data table, and you should get every row for the same cohort displaying the same number
Add Sales onto Text to get the value of sales made by the customer in each cohort in each quarter. The ‘customer lifetime value’ we need is defined as the total sales so far / number of customers in the cohort.
Remove the QUARTER(Order Date) field from the table, as we’re not going to need this for the display, and it’ll affect the next steps if it’s left.
To get the cumulative sales, we need a Running Total Quick Table Calculation. Click on the Sales pill on the Text shelf and select Quick Table Calculation -> Running Total. The click again and Compute By -> QUARTERS SINCE BIRTH. Add Sales back into the table, so you can see the quarterly Sales value and how it’s cumulating until it reaches the next cohort.
We’ve now got the building blocks we need for the CLTV value we need to plot
Avg Lifetime Value
RUNNING_SUM(SUM([Sales])) / SUM([CUSTOMERS])
Note – I purposefully haven’t called this field what you might expect, as I’m going to ‘fill in the gaps’ that Ann describes in the requirements, and I’ll use that name then.
Pop this field into the table above, again setting the table calculation to compute by QUARTERS SINCE BIRTH
You can now use the data table above to validate the calculation is what you expected.
Now let’s build the viz out.
On a new sheet
QUARTERS SINCE BIRTH to Columns
ACQUISITION QUARTER (exact date, discrete blue pill) to Rows
Avg Lifetime Value to Text, setting the table calculation to Compute ByQUARTERS SINCE BIRTH
From this basic text table, you can see the ‘blank’ fields, Ann mentioned. In the data table view, it’s not so obvious. The blank is there because there are no sales in those quarters for those cohorts. To fix we need another table calculation
CUSTOMER LIFETIME VALUE (CLTV)
IF ISNULL([Avg Lifetime Value]) AND NOT ISNULL(LOOKUP([Avg Lifetime Value],-1)) AND NOT ISNULL(LOOKUP([Avg Lifetime Value],1))
THEN LOOKUP([Avg Lifetime Value],-1) ELSE [Avg Lifetime Value] END
This says, if the Avg Lifetime Value field is NULL but neither the previous or the subsequent values are NULL, then use the Avg Lifetime Value value from the previous column (LOOKUP).
Replace the Avg Lifetime Value with the CUSTOMER LIFETIME VALUE (CLTV) field (setting the Compute By again), and the empty spaces have disappeared.
If you hover over the cells in the lower right hand side of the view, you’ll see tooltips showing, indicating that a mark has been drawn on the viz with Null data. To fix this, add CUSTOMER LIFETIME VALUE (CLTV) to the Filter shelf and specify non-null values only to show via the Special tab.
Now if you hover over that area you don’t get any tooltips displaying, as there aren’t any marks there.
Now it’s just a case of formatting the viz a bit more
Add CUSTOMERS to Rows
Add CUSTOMER LIFETIME VALUE (CLTV) to the Colour shelf by holding down the Ctrl key then clicking on the field that’s already on the Text shelf, and dragging via the mouse onto the Colour shelf. Using Ctrl in this way has the effect of copying the field including the table calculation settings, so you don’t need to apply them again. This will change the colour of the Text.
Then change the mark type to Square, which will then fill out the background based on the colour.
Then edit the colour legend to the relevant palette (which you may need to install via Ann’s link).
Set the border of the mark via the Colour shelf to white
Remove the row & column dividers
Set the row Axis Ruler to a dark black/grey line
Format the 1st 2 columns so the font is the same and centred. Widen the columns if required.
Update the tooltip
And then you should be ready to add the viz to your dashboard. My published version is here.
This blog is a bit more detailed that my recent posts, but I’m also conscious I’ve skipped over some bits that if you’re brand new to Tableau, you may not be sure how to do. Feel free to add comments if you need help!
For this week’s #WOW2020 challenge, Lorna Brown asked us to recreate a waterfall chart – a chart style that hasn’t featured in many previous challenges (if at all), and is always a useful one to know how to build.
I’m familiar with these, and this challenge didn’t cause me too many issues, so this blog is going to be brief.
Building the waterfall
Small multiple / grid layout
Adding the month label
Building the waterfall
So I’d built out the basic waterfall for each month and day by plotting Year(Order Date), Month(Order Date) and Day(Order Date) on Columns. The Day(Order Date) field was set to Show Missing Values so each day without an order was still plotted, and I was trying to figure out how to get the additional ‘long’ bar at the end.
I worked out it was essentially a ‘total’ bar and when I duplicated my data as crosstab and played round with the data in a tabular form, I got the subtotals I needed displayed.
But I seemed to be having issues displaying these on the chart view. So I turned to my usual route, Google, and had a search, and came across this blog from Tim Ryan at The Data School, which gives you the complete guide to building the waterfall, so there’s no need for me to repeat it all – thanks Tim! 🙂
My issue was I had a green continuous Day(Order Date) field rather than a blue discrete one – doh!
The only couple of things you need to make note of – you need to ensure you have 0 displayed for the missing dates
Actual Profit
ZN(SUM([Profit]))
and the gantt bars should be coloured red for negative profit, blue for positive and grey for the missing days
Colour
IF SUM([Profit])<0 THEN ‘Red’ ELSEIF SUM([Profit]) > 0 THEN ‘Blue’ ELSE ‘Grey’ END
Small multiple / grid layout
For this you need fields to add to the Rows and Columns shelf that position the month in the appropriate cell.
The Quarter(Order Date) (blue discrete) on Rows, is just used to define the row a month lands in.
You then need
Cols
IF MONTH([Order Date])%3 = 0 THEN 3 ELSE MONTH([Order Date])%3 END
which assigns each month a value of 1,2 or 3. You’ll need this on the Columns shelf.
Adding the month label
The label shows the month and the total profit in the month, so I created an LOD for this
From this I wanted the maximum value of all the monthly profits
Max Monthly Profit in Year
{FIXED Year([Order Date]): MAX([Profit for Month])}
I then used a dual axis to plot this field on the Rows, set the mark type to a line and set the opacity of the line colour to 0%, so it disappears.
The month and value were then added to the Label shelf and the label set to Label start of line only and also right aligned to get the required positioning.
And that’s it. I said this would be brief 🙂 My published viz is here.
It’s Community Month over at #WOW HQ this month, which means guest posters, and Kyle Yetter kicked it all off with this challenge. Having completed numerous YoY related workbooks both through work and previous #WOW challenges, this looked like it might be relatively straight forward on the surface. But Kyle threw in some curve balls, which I’ll try to explain within this blog. The points I’ll be focussing on
YoY % calculation for colouring the map
Displaying the circles on the map
Restricting the Date parameter to 1st Jan – 14th July only
Showing Daily or Weekly dates on the viz in tooltip
Restricting to full weeks only (in weekly view)
YoY % calculation
The data provided includes dates from 1st Jan 2019 to 21st July 2020. We need to be able to show Current Year (CY) values alongside Previous Year (PY) values and the YoY% difference. I built up the following calculations for all this
Today
#2020-07-15#
This is just hardcoded based on the requirement. In a business scenario where the data changes, you may use the TODAY() function to get the current date.
Current Year
YEAR([Today])
simply returns 2020, which I could have hardcoded as well, but I prefer to build solutions as if the data were more dynamic.
CY
IF YEAR([Subscription Date]) = [Current Year] THEN [Subscription] END
stores the value of the Subscription field but only for records associated to 2020
PY
IF YEAR([Subscription Date]) = [Current Year]-1 THEN [Subscription] END
stores the value of the Subscription field but only for records associated to 2019 (ie 2020-1)
YoY%
(SUM([CY])- SUM([PY]))/SUM([PY])
format this to a percentage with 0 decimal places. This ultimately is the measure used to colour the map. CY, PY & YoY% are also referenced on the Tooltip.
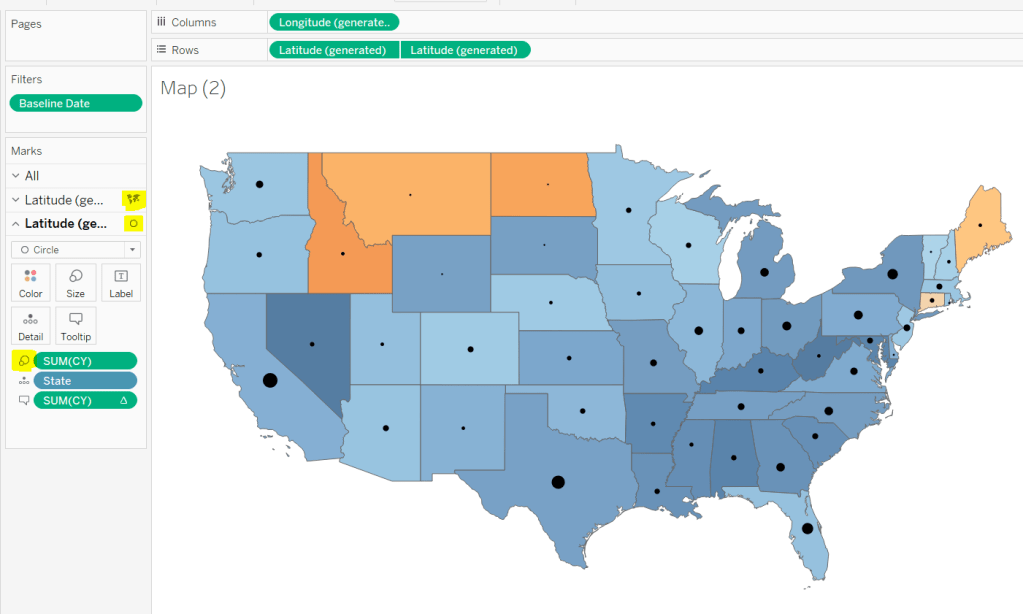
Displaying circles on the map
This is achieved using a dual axis map (via a second instance of the Latitude pill on Rows). One ‘axis’ is a map mark type coloured by the YoY% and the other is a circle mark type, sized by CY, explicitly coloured black.
The Tooltip for the circle mark type also shows the % of Total subscriptions for the current year, which is a Percent of Total Quick Table Calculation
Restricting the Date parameter to 1st Jan – 14th July only
As mentioned the Subscription Date contains dates from 01 Jan 2019 to 21 July 2020, but we can’t simply add a filter restricting this date to 01 Jan 20 to 14 Jul 20 as that would remove all the rows associated to the 2019 data which we need available to provide the PY and YoY% values.
So to solve this we need a new date field, and we need to baseline / normalise the dates in the data set to all align to the same year.
Baseline Date
//set all dates to be based on current year MAKEDATE([Current Year], MONTH([Subscription Date]), DAY([Subscription Date]))
So if the Subscription Date is 01 Jan 2019, the equivalent Baseline Date associated will be 01 Jan 2020. The Subscription Date of 01 Jan 2020 will also have a Baseline Date of 01 Jan 2020.
We also want to ensure we don’t have dates beyond ‘today’
Include Dates < Today
[Baseline Date]< [Today]
Add Include Dates < Today to the Filter shelf, and set to True.
Add Baseline Date to the Filter shelf, choose Range of Dates , and by default the dates 01 Jan 2020 to 14 Jul 2020 should be displayed
Select to Show Filter, and when the filter displays, select the drop down arrow (top right) and change to Only Relevant Values
Whilst you can edit the start and end dates in the filter to be before/after the specific dates, this won’t actually use those dates, and the filter control slider can only be moved between the range we want.
The Baseline Date field should then be custom formatted to mmmm dd to display the dates in the January 01 format.
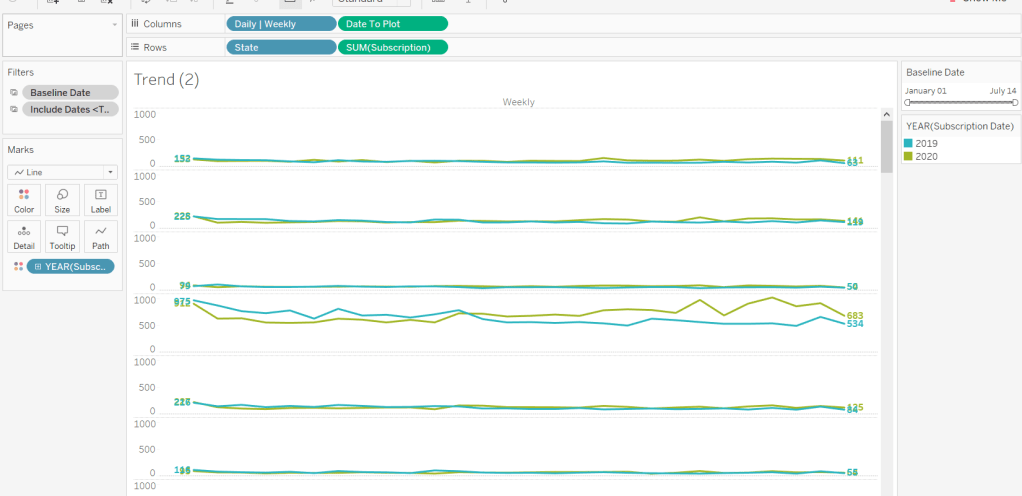
Showing Daily or Weekly dates on the viz in tooltip
The requirements state that if the date range selected is <=30 days, the trend chart shown on the Viz in Tooltip should display daily data, otherwise it should be weekly figures, where the week ‘starts’ on the minimum date selected in the range.
There’s a lot going on to meet this requirement.
First up we need to be able to identify the min & max dates selected by the user via the Baseline Date filter.
This did cause me some trouble. I knew what I wanted, but struggled. A FIXED LOD always gave me the 1st Jan 2020 for the Min Date, regardless of where I moved the slider, whereas a WINDOW_MIN() table calculation function caused issues as it required the data displayed to be at a level of detail that I didn’t want.
A peak at Kyle’s solution and I found he’dadded the date filters to context. This means a FIXED LOD would then return the min & max dates I was after.
Min Date
{MIN([Baseline Date])}
Note this is a shortened notation for {FIXED : MIN([Baseline Date])}
Max Date
{MAX([Baseline Date])}
With these, we can work out
Days between Min & Max
DATEDIFF(‘day’,[Min Date], [Max Date])
which in turn we can categorise
Daily | Weekly
IF [Days between Min & Max]<=30 THEN ‘Daily’ ELSE ‘Weekly’ END
We also need to understand the day the weeks will start on.
Day of Week Min Date
DATEPART(‘weekday’,[Min Date])
This returns a number from 1 (Sunday) to 7 (Saturday) based on the Min Date selected.
Using this we can essentially ‘categorise’ and therefore ‘group’ the Baseline Date into the appropriate week.
Baseline Date Week
CASE [Day of Week Min Date] WHEN 1 THEN DATETRUNC(‘week’,([Baseline Date]),’Sunday’) WHEN 2 THEN DATETRUNC(‘week’,([Baseline Date]),’Monday’) WHEN 3 THEN DATETRUNC(‘week’,([Baseline Date]),’Tuesday’) WHEN 4 THEN DATETRUNC(‘week’,([Baseline Date]),’Wednesday’) WHEN 5 THEN DATETRUNC(‘week’,([Baseline Date]),’Thursday’) WHEN 6 THEN DATETRUNC(‘week’,([Baseline Date]),’Friday’) WHEN 7 THEN DATETRUNC(‘week’,([Baseline Date]),’Saturday’) END
Ideally we want to simplify this using something like DATETRUNC(‘week’, [Baseline Date], DATEPART(‘weekday’, [Min Date])), but unfortunately, at this point, Tableau won’t accept a function as the 3rd parameter of the DATETRUNC function.
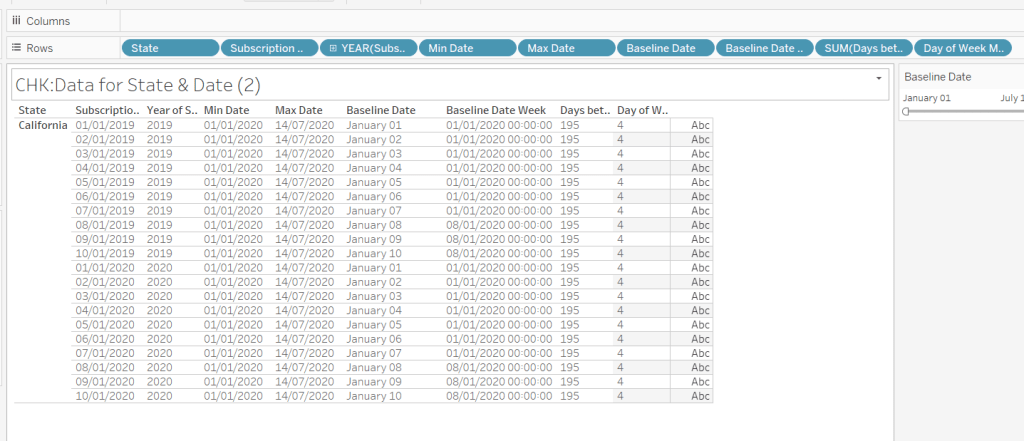
Let’s just have a look at what we’ve got so far
Rows for California only showing the Subscription Dates from 01 Jan 2019 – 10 Jan 2019 and 01 Jan 2020 to 10 Jan 2020. Min & Max date for all rows are identical and matches the values in the filter. The Baseline Date field for both 01 Jan 2019 and 01 Jan 2020 is January 01. The Baseline Date Week for 01 Jan 2019 – 07 Jan 2019 AND 01 Jan 2020 – 07 Jan 2020 is 01 Jan 2020. The other dates are associated with the week starting 08 Jan 20202.
So now we have all this information, we need yet another date field that will be plotted on the date axis of the Viz in Tooltip.
Date to Plot
IF [Days between Min & Max] <=30 THEN ([Baseline Date]) ELSE [Baseline Date Week] END
If you add this field to the tabular display I built out above, you can see how the value changes as you move the filter dates to be within 30 days of each other and out again.
When added to the actual viz, this field is formatted to dd mmm ie 01 Jan, and then is plotted as a continuous, exact date (green pill) field on the Columns alongside the Daily | Weekly field, with State & Subscription on Rows. The YEAR(Subscription Date) provides the separation of the data into 2 lines.
Restricting to full weeks only (in weekly view)
The requirements state only full weeks (ie 7 days of data) should be included when the data is plotted at a weekly level. For this we need to ascertain the ‘week’ the maximum date falls in
Max Date Week
CASE [Day of Week Min Date] WHEN 1 THEN DATETRUNC(‘week’,([Max Date]),’Sunday’) WHEN 2 THEN DATETRUNC(‘week’,([Max Date]),’Monday’) WHEN 3 THEN DATETRUNC(‘week’,([Max Date]),’Tuesday’) WHEN 4 THEN DATETRUNC(‘week’,([Max Date]),’Wednesday’) WHEN 5 THEN DATETRUNC(‘week’,([Max Date]),’Thursday’) WHEN 6 THEN DATETRUNC(‘week’,([Max Date]),’Friday’) WHEN 7 THEN DATETRUNC(‘week’,([Max Date]),’Saturday’) END
so if the maximum date selected is a Thursday (eg Thurs 11th June 2020) but the minimum date happens to be a Tuesday, then the week starts on a Tuesday, and this field will return the previous Tuesday date (eg Tues 9th June 2020).
And then to restrict to complete weeks only…
Full Weeks Only
IF [Daily | Weekly]=’Weekly’ THEN [Date To Plot]< [Max Date Week] ELSE TRUE END
If we’re in the ‘weekly’ mode, the Date To Plot field will be storing dates related to the start of the week, so will return true for all records where the field is less than the week of the max date. Otherwise if we’re in ‘daily’ mode we just want all records.
This field is added to the Filter shelf and set to true.
Hopefully that covers off all the complicated bits you need to know to complete this challenge. My published solution is here.
Week 39 of #WorkoutWednesday was set by Lorna this week. Details of the challenge and a description of what a BCG Growth Share Matrix is here.
The main complexity of this challenge is the calculations, and more so with Lorna’s stipulation ‘no table calcs allowed’.
I started using Tableau before LoDs were introduced, so I tend to be much more comfortable with Table Calcs than I do with LoDs; I know there are many people who are the other way round.
So, let’s get started. In the interest of time (it’s now Sunday afternoon, and I’ve dipped into this challenge on & off since Wednesday), I’m going to focus on the calcs involved in achieving my solution, and not necessarily going into the detail of putting it all together on the Viz.
Sales Scatter
To build the Sales Scatter Plot, we need the following information to help get the %growth and %market share values :
The total sales across all the specified years per subcategory
The sales for the latest year per subcategory
The total sales for the previous years per subcategory
The overall total sales across all the specified years
The number of years to compare against is set by a parameter to be 2,3,or 4 years (No.of Years).
To limit the data just to these years, I created a Dates To Include as
YEAR([Order Date]) >= [Max Year in Dataset] – ([No of Years]-1)
Max Year in Dataset is another field that I could have simply hardcoded to 2019, but I decided to be more dynamic, and derive it using an LoD
YEAR({FIXED: MAX([Order Date])})
which gets the latest Order Date in the data and then retrieves the Year part of it, which happens to be 2019 in this instance. Dates To Include is then True if the year of the order date is greater than, or equal to, the maximum year less one less than the No of Years param.
Eg if No of Years = 2, then Dates to Include is True if the year of the order date >= 2019 – (2-1) = 2019-1 = 2018.
if No of Years = 4, then Dates to Include is True if the year of the order date >= 2019 – (4-1) = 2019-3= 2016.
To sense check the numbers I need, I built a tabular view by Sub Category adding Dates to Include = True to the filters shelf.
Total sales across all the specified years per subcategory
is simply achieved by adding SUM([Sales]) to the view.
Sales Latest Year
The sales for the latest year per subcategory is
IF YEAR([Order Date]) = [Max Year in Dataset] THEN [Sales] END
Sales Previous Years
The sales for the previous years per subcategory is then just the opposite
IF YEAR([Order Date]) <> [Max Year in Dataset] THEN [Sales] END
The value of this field ultimately changes as the No of Years parameter changes. If No of Years = 2, then this will contain the 2018 sales, if its 3, then it will contain the sum of the sales in 2017 & 2018 etc.
The Growth % is stated as being the change for the latest year in comparison to the average sales of the previous years. So next I need
Average Sales Previous Years
SUM([Sales Previous Years])/([No of Years]-1)
Note the [No of Years]-1, as when comparing across 2 years, I’m really only being asked to compare 2019 with the previous year, ie 2018.
The difference of the latest year compared to the average, as a proportion of the average.
Now we need the Market Share of Sales. This would usually be a pretty simple Percent of Total quick table calculation on SUM([Sales]), but I’ve been challenged to do this without table calcs. So an LoD is needed instead. I created
Sales All Years
{FIXED [Dates to Include]:SUM([Sales])}
which gives me my total sales across the specified years, at the ‘overall’ level.
From this I can calculate
Market Share Sales
SUM([Sales])/SUM([Sales All Years])
The table below gives the breakdown of all these fields at a sub-category level for 2 years
Next step is to categorise each row into Cash Cows, Dogs, Question Marks or Stars based on their % Growth & % Market Share values. Lorna stated that 7% should be considered the mid-point for % Market Share, but that the Growth mid point should be half of the maximum growth value.
From the table above, 64.8% (against appliances) is the maximum value in the set, so I need a new field against each row that outputs 32.4%. Once again, with Table Calcs I would just have used WINDOW_MAX to find the max and halve it. But instead I needed another LOD, this one a bit more complex…
I find INCLUDE and EXCLUDE LoDs a bit of a black art, and there may well have been another way to do this, but it was a bit of trial and error in the end, and so once it gave the value I was after, I stuck with it 🙂 I’ve tried to write some sentences to explain it better, but can’t 😦
So with the mid point defined, the categorisation is then
Sales Category (Sub Cat)
IF [Growth Sales]<=MIN([Mid Sales Growth Constant (Sub Cat)]) AND [Market Share Sales]<=MIN([Mid Market Share Constant]) THEN ‘Dogs’ ELSEIF [Market Share Sales]<=MIN([Mid Market Share Constant]) AND [Growth Sales]>MIN([Mid Sales Growth Constant (Sub Cat)]) THEN ‘Question Marks’ ELSEIF [Growth Sales]>MIN([Mid Sales Growth Constant (Sub Cat)]) AND [Market Share Sales]>MIN([Mid Market Share Constant]) THEN ‘Stars’ ELSE ‘Cash Cows’ END
This is all the information now needed to plot the Sales Scatter chart. Custom shapes were sourced from flaticon.com and I used Paint to colour and resize them appropriately, before saving them into a folder in the Shapes folder of the My Tableau Repository directory on my laptop.
Order Scatter
The steps for creating the Orders scatter are the same in principle. I need to find
The total orders across all the specified years per subcategory
The number of orders for the latest year per subcategory
The number of orders for the previous years per subcategory
The overall number of orders across all the specified years
However in doing this I got quite different numbers from Lorna, and its due to how you choose to count orders. Unlike a sales value, where the value is just attributed to a single line in the data set, an Order ID can span multiple lines, which means they can span sub-categories too. Eg imagine you have
Order A – contains 2 line of appliances, and 1 line of phones
Order B – contains 1 line of appliances.
How many orders are there? Answer = 2
How many order lines are there? Answer = 4
How many orders contain appliances? Answer = 2 (100%)
How many order lines contain appliances? Answer = 3 (75%)
How many orders contain phones? Answer 1 (50%)
How many order lines contain phones? Answer 1 (25%)
So when it comes to the ‘market share %’, should I be considering order lines (which means it’ll sum to 100%) or distinct orders which means it’ll sum to more than 100%.
I wrestled with this, and ultimately concluded, this challenge is purely for illustrative purposes, and to stick with my original assumption based on distinct orders (which I’d already calculated before finding the discrepancy). So my Market Share % won’t sum to 100%, and probably isn’t really a definition of Market Share, but I made peace with myself and moved on 🙂
# Orders
COUNTD([Order ID])
Orders Latest Year
COUNTD(IF YEAR([Order Date]) = [Max Year in Dataset] THEN [Order ID] END)
Orders Previous Years
COUNTD(IF YEAR([Order Date]) <> [Max Year in Dataset] THEN [Order ID] END)
Once again the Market share mid point was defined to be a 7% constant, while the growth % mid point needed to be half the max value, which in this instance based on the above, was 1/2 of 51.2%. The same type of LOD was required which gave me
IF [Growth Orders]<=MIN([Mid Orders Growth Constant (Sub Cat)]) AND [Market Share Orders]<=MIN([Mid Market Share Constant]) THEN ‘Dogs’ ELSEIF [Market Share Orders]<=MIN([Mid Market Share Constant]) AND [Growth Orders]>MIN([Mid Orders Growth Constant (Sub Cat)]) THEN ‘Question Marks’ ELSEIF [Growth Orders]>MIN([Mid Orders Growth Constant (Sub Cat)]) AND [Market Share Orders]>MIN([Mid Market Share Constant]) THEN ‘Stars’ ELSE ‘Cash Cows’ END
Top 20 Manufacturers Bar Chart
To create the bar chart, I created a new field Manufacturer-SubCat as
[Manufacturer] + ‘ (‘ + [Sub-Category] + ‘)’
I then set about creating the same data tables as I’ve included above, one for Sales and one for Orders.
The majority of the measures used were the same, but when it came to determining the growth mid-point, I found creating a separate field was simpler than trying to use a single field that worked across both Sub-Category and Manufacturer-SubCat. I followed the same methodology though:
I also found though that the 7% market share constant didn’t really give me the split, so I decided a 3% constant would be better to give me categorisations at this level into each bracket. As I had different comparison values, I needed new categorisation fields too.
Sales Category (Manu Sub Cat)
IF [Growth Sales]<=MIN([Mid Sales Growth Constant (Manu Sub Cat)]) AND [Market Share Sales]<=MIN([Mid Market Share Constant (Manu Sub Cat)]) THEN ‘Dogs’ ELSEIF [Market Share Sales]<=MIN([Mid Market Share Constant (Manu Sub Cat)]) AND [Growth Sales]>MIN([Mid Sales Growth Constant (Manu Sub Cat)]) THEN ‘Question Marks’ ELSEIF [Growth Sales]>MIN([Mid Sales Growth Constant (Manu Sub Cat)]) AND [Market Share Sales]>MIN([Mid Market Share Constant (Manu Sub Cat)]) THEN ‘Stars’ ELSE ‘Cash Cows’ END
Orders Category (Manu Sub Cat)
IF [Growth Orders]<=MIN([Mid Orders Growth Constant (Manu Sub)]) AND [Market Share Orders]<=MIN([Mid Market Share Constant (Manu Sub Cat)]) THEN ‘Dogs’ ELSEIF [Market Share Orders]<=MIN([Mid Market Share Constant (Manu Sub Cat)]) AND [Growth Orders]>MIN([Mid Orders Growth Constant (Manu Sub)]) THEN ‘Question Marks’ ELSEIF [Growth Orders]>MIN([Mid Orders Growth Constant (Manu Sub)]) AND [Market Share Orders]>MIN([Mid Market Share Constant (Manu Sub Cat)]) THEN ‘Stars’ ELSE ‘Cash Cows’ END
To Sort the Manufacturer-SubCategory data by Sales or Orders, I created a SORT BY parameter with values of Sales and Orders.
I then created
Sort Value
IF [Sort] = ‘Order’ THEN [# Orders] ELSE SUM([Sales]) END
On the Manufacturer-SubCat field, I then set the Sort by property to be
Manufacturer-SubCat was then also added to the Filters shelf, with the filter set to
And that covers the main calcs and complexities that went into my version/interpretation of this challenge. I hate it when I can’t get the numbers to match 😦 but ultimately now feel comfortable with what I did and I hope it might explain why some of you may have got differences too…
My version of the viz is here, and I’ve included additional detail on the tooltips too which should show the numbers that went into the % calcs for each mark.


















































































{kind=link}
{kind=link}